Wiki Articles
a2a compliancea2a protocolabstraction erroraccessibility treesadaptive d2snapadaptive downsamplingagent cardagent cardsagent evaluation frameworksagent evaluationagent memory systemsagent skillsagent to agent protocolagent training infrastructureagentic webagentrewardbenchapi design and documentationapi designapproximate state abstractionassociative memoryattention mechanismsauto research agentsauto researchautomated benchmark constructionautonomous software engineeringbehavioral pattern analysisbenchmark constructionbenchmark contaminationbenchmark designbrowser automation frameworksbrowser automationchecklist based vlm verificationchunk wise updatescode generation and completioncode generationcohen s kappacollaborative aicomputer use agentscomputer usecomputer vision for guicomputer vision for ui understandingcomputer vision for uicomputer vision for uiscomputer vision modelsconcept based modelsconcept bottleneck modelsconcept selectioncontainer orchestrationcontamination filteringcontext parallelismcontext window optimizationcontinual learningcreation audit loopcritical point violationscross domain collaborationcross origin securitycross repository collaborationcross software generalizationcss selectorscuaverifierbenchd2snap algorithmd2snapdata flywheeldecision relevant conceptsdependency managementdigital asset agentizationdistributed systemsdocument object modeldom downsamplingdom snapshotsdownsamplingdynamic adaptationeconomic impact assessmentelement classificationelement extraction techniqueselement extractionenvironment automationenvironment blockersenvironment setupenvironment virtualizationerror taxonomyevaluation metricsfalse positive ratefast weightsfeature selectiongdp based evaluationgdp grounded benchmarkinggdp grounded evaluationgdp grounded software selectiongradient descentgrounded gui snapshotsgrounded interactiongui agent traininggui agentsgui snapshotshallucination detectionhalton sequenceshtml parsing and processinghtml parsinghtml preprocessinghtml semanticshtml serializationhuman ai agreementhuman ai collaborationin context learninginduction headsinter annotator agreementinteractive environmentsinteractive task benchmarkinginterpretable machine learninginterpretable reinforcement learninglarge language model traininglarge language modelslinear attentionllm based interactionllm context windowsllm ground truthllm web agentslong context language modelinglong context modelinglong horizon planninglong horizon task planningmarkov decision processesmemory augmentationmicroservices architecturemixed integer linear programmingmlp blocksmlp repurposingmodel context protocolmulti agent environment creationmulti agent systemsmulti modal ai systemsmulti modal aimulti modal foundation modelsmulti modal llmsmulti turn reinforcement learningmultimodal evaluationmultimodal llm capabilitiesmultimodal llmsnext token prediction ntpnext token predictiononline mind2weborchestration mechanismsparameter interpolationpolicy learningprivileged information verificationprivileged informationprocess vs outcome rewardspropose and amplify strategyproximal policy optimizationq distancereact frameworkreader modereader viewsreinforcement learning from human feedbackreinforcement learning interpretabilityreinforcement learningrepository level developmentrepository miningrepository utilizationreward designrotary position embeddingsrubric designrubric generationruler benchmarkscreenshot analysisscreenshot context managementscreenshot relevance matrixservice discoveryside effect detectionsignal processingskill constructionsliding window attentionsoftware engineering automationsoftware environment virtualizationstate abstractionstate abstractionsstate space modelstest time auditingtest time interventiontest time training ttttest time trainingtextrank algorithmtextranktoken optimization for llmstoken optimizationtool extractiontool use in ai systemstrajectory distillationtrajectory verificationtransformer architectureui feature classificationui feature engineeringui feature extractionui feature semanticsuniversal verifiervalue functionsvision language model architecturevision language modelsvisual groundingvisualwebarenavlm verificationweb agent snapshotsweb agentsweb application state serializationweb application stateweb automation testingweb automationweb scrapingweb ui testingwebarenawebjudgewebvoyageradaptive learning infrastructureadaptive training paradigms for dynamic environmentsagent interoperability standardscontext aware state compressioncontext compression for interactive aicross modal state representation in gui understandingcross platform gui understandingdata contamination and benchmark integritydom processing and token efficiencydynamic adaptation during inferencedynamic adaptation in ai systemseconomic driven ai research methodologyeconomic driven research methodologyeconomic impact as research methodologyeconomic impact driven research prioritizationevaluation infrastructure challenges for gui agentshierarchical agent control systemshierarchical learning and credit assignment in complex environmentshierarchical learning and credit assignmenthierarchical learning systems for complex agent behaviorsinformation asymmetry in task generationinformation compression for interactive aiinterpretability and explainability in gui decision makinginterpretable decision architectureinterpretable decision making in reinforcement learningmemory and context management in long horizon tasksmemory architecture for long horizon agent tasksmulti agent coordination for environment creationmulti agent environment creationmulti agent orchestration in environment creation and evaluationmulti modal gui understandingmulti modal perception in gui agentsmulti modal state representation for web agentspointing and spatial reasoning in vision language modelsscalable synthetic data generation for agent trainingscale performance trade offs in agent trainingself evolving agent systemsself improving agent ecosystemsself improving agent training ecosystemsstate representation in gui agentsstate space compression for gui agentssynthetic environment generation for agent trainingsynthetic training ecosystem architecturetoken efficiency and context optimizationverification and quality assurance architectureverification and quality control in agent evaluationverification and quality control in autonomous agent systemsverification infrastructure for autonomous agentsactionengine from reactive to programmatic gui agents via state machine memoryagentization of digital assets for the agentic web concepts techniques and benchagentsynth scalable task generation for generalist computer use agentsama bench evaluating long horizon memory for agentic applicationsarxiv 250411543arxiv 260406126autonomous continual learning of computer use agents for environment adaptationautowebworld synthesizing infinite verifiable web environments via finite statebeyond pixels exploring dom downsampling for llm based web agentscode2world a gui world model via renderable code generationcomputer using world modelcua suite massive human annotated video demonstrations for computer use agentsefficient agent training for computer useevoskill automated skill discovery for multi agent systemsfrom self evolving synthetic data to verifiable reward rl post training multi tufrontier rl is cheaper than you thinkgeneralizable end to end tool use rl with synthetic codegymgithub karpathyautoresearch ai agents running research on single gpu nanochat trgithub web arena xwebarena infinity an approach to utomatically generating browsgtr guided thought reinforcement prevents thought collapse in rl based vlm agentgui libra training native gui agents to reason and act with action aware supervihalluminate rl environments for financial serviceshiper hierarchical reinforcement learning with explicit credit assignment for lain place test time traininginfiniteweb scalable web environment synthesis for gui agent traininginsta towards internet scale training for agentsintrinsic credit assignment for long horizon interactionlonghorizonui a unified framework for robust long horizon taskmobile agent v35 multi platform fundamental gui agentsmolmopoint better pointing architecture for vision language models or ai2openclaw rl train any agent simply by talkingprorl agent rollout as a service for rl training of multi turn llm agentsreal benchmarking autonomous agents on deterministic simulationsselecting decision relevant concepts in reinforcement learningstate of rl for reasoning llms or a weersthe art of building verifiers for computer use agentstopocurate modeling interaction topology for tool use agent trainingui tars 2 technical report advancing gui agent with multi turn reinforcement leaui voyager a self evolving gui agent learning via failed experiencewebfactory automated compression of foundational language intelligence into grouwebgym scaling training environments for visual web agents with realistic tasksRaw Sources
actionengine-from-reactive-to-programmatic-gui-agents-via-state-machine-memory.mdimg-0.pngimg-1.pngimg-2.pngimg-3.pngimg-4.pngagentization-of-digital-assets-for-the-agentic-web-concepts-techniques-and-bench.mdagentsynth-scalable-task-generation-for-generalist-computer-use-agents.mdama-bench-evaluating-long-horizon-memory-for-agentic-applications.mdarxiv-250411543.mdarxiv-260406126.mdautonomous-continual-learning-of-computer-use-agents-for-environment-adaptation.mdautowebworld-synthesizing-infinite-verifiable-web-environments-via-finite-state-.mdbeyond-pixels-exploring-dom-downsampling-for-llm-based-web-agents.mdimg-0.pngimg-1.pngimg-2.pngimg-3.pngimg-4.pngimg-5.pngimg-6.pngimg-7.pngimg-8.pngcode2world-a-gui-world-model-via-renderable-code-generation.mdcomputer-using-world-model.mdcua-suite-massive-human-annotated-video-demonstrations-for-computer-use-agents.mdefficient-agent-training-for-computer-use.mdevoskill-automated-skill-discovery-for-multi-agent-systems.mdfrom-self-evolving-synthetic-data-to-verifiable-reward-rl-post-training-multi-tu.mdfrontier-rl-is-cheaper-than-you-think.mdgeneralizable-end-to-end-tool-use-rl-with-synthetic-codegym.mdimg-0.pnggithub-karpathyautoresearch-ai-agents-running-research-on-single-gpu-nanochat-tr.mdimg-0.gifimg-1.pngimg-2.pngimg-3.pngimg-4.pnggithub-web-arena-xwebarena-infinity-an-approach-to-utomatically-generating-brows.mdgtr-guided-thought-reinforcement-prevents-thought-collapse-in-rl-based-vlm-agent.mdgui-libra-training-native-gui-agents-to-reason-and-act-with-action-aware-supervi.mdimg-0.pngimg-1.pngimg-10.pngimg-2.pngimg-3.pngimg-4.pngimg-5.pngimg-6.pngimg-7.pngimg-8.pngimg-9.pnghalluminate-rl-environments-for-financial-services.mdhiper-hierarchical-reinforcement-learning-with-explicit-credit-assignment-for-la.mdin-place-test-time-training.mdinfiniteweb-scalable-web-environment-synthesis-for-gui-agent-training.mdinsta-towards-internet-scale-training-for-agents.mdimg-0.pngimg-1.pngimg-2.pngimg-3.pngimg-4.pngimg-5.pngimg-6.pngimg-7.pngimg-8.pngimg-9.pngintrinsic-credit-assignment-for-long-horizon-interaction.mdlonghorizonui-a-unified-framework-for-robust-long-horizon-task.mdmobile-agent-v35-multi-platform-fundamental-gui-agents.mdmolmopoint-better-pointing-architecture-for-vision-language-models-or-ai2.mdopenclaw-rl-train-any-agent-simply-by-talking.mdprorl-agent-rollout-as-a-service-for-rl-training-of-multi-turn-llm-agents.mdreal-benchmarking-autonomous-agents-on-deterministic-simulations.mdselecting-decision-relevant-concepts-in-reinforcement-learning.mdimg-0.jpgstate-of-rl-for-reasoning-llms-or-a-weers.mdthe-art-of-building-verifiers-for-computer-use-agents.mdtopocurate-modeling-interaction-topology-for-tool-use-agent-training.mdui-tars-2-technical-report-advancing-gui-agent-with-multi-turn-reinforcement-lea.mdui-voyager-a-self-evolving-gui-agent-learning-via-failed-experience.mdwebfactory-automated-compression-of-foundational-language-intelligence-into-grou.mdwebgym-scaling-training-environments-for-visual-web-agents-with-realistic-tasks.md{kind=link}
{kind=link}
{kind=link}
{kind=link}
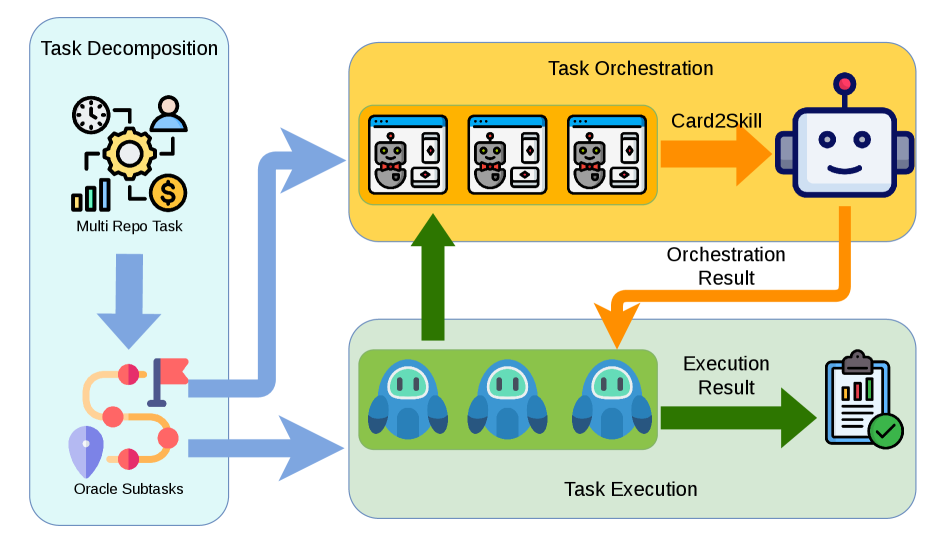{kind=link}
{kind=link}
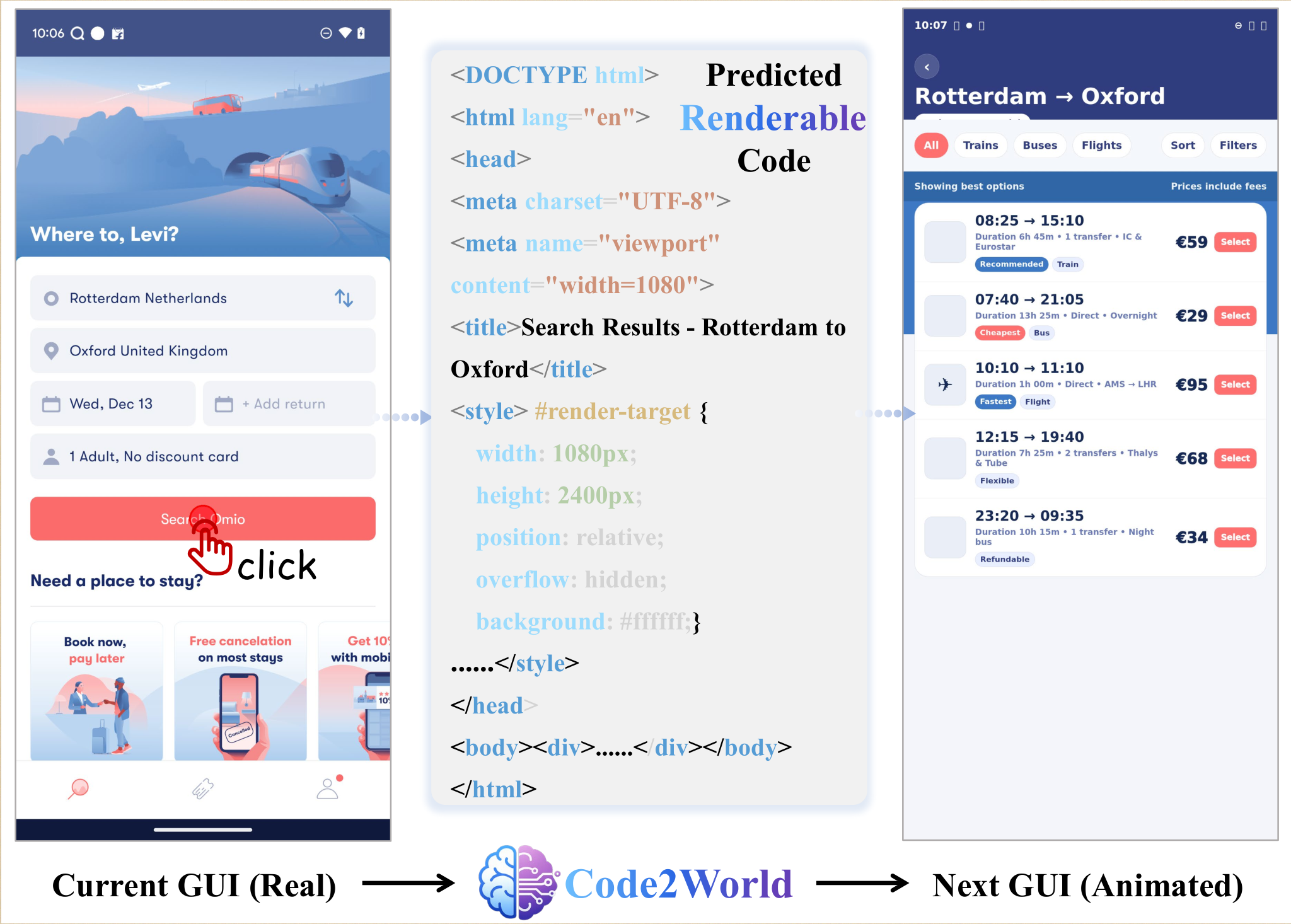{kind=link}
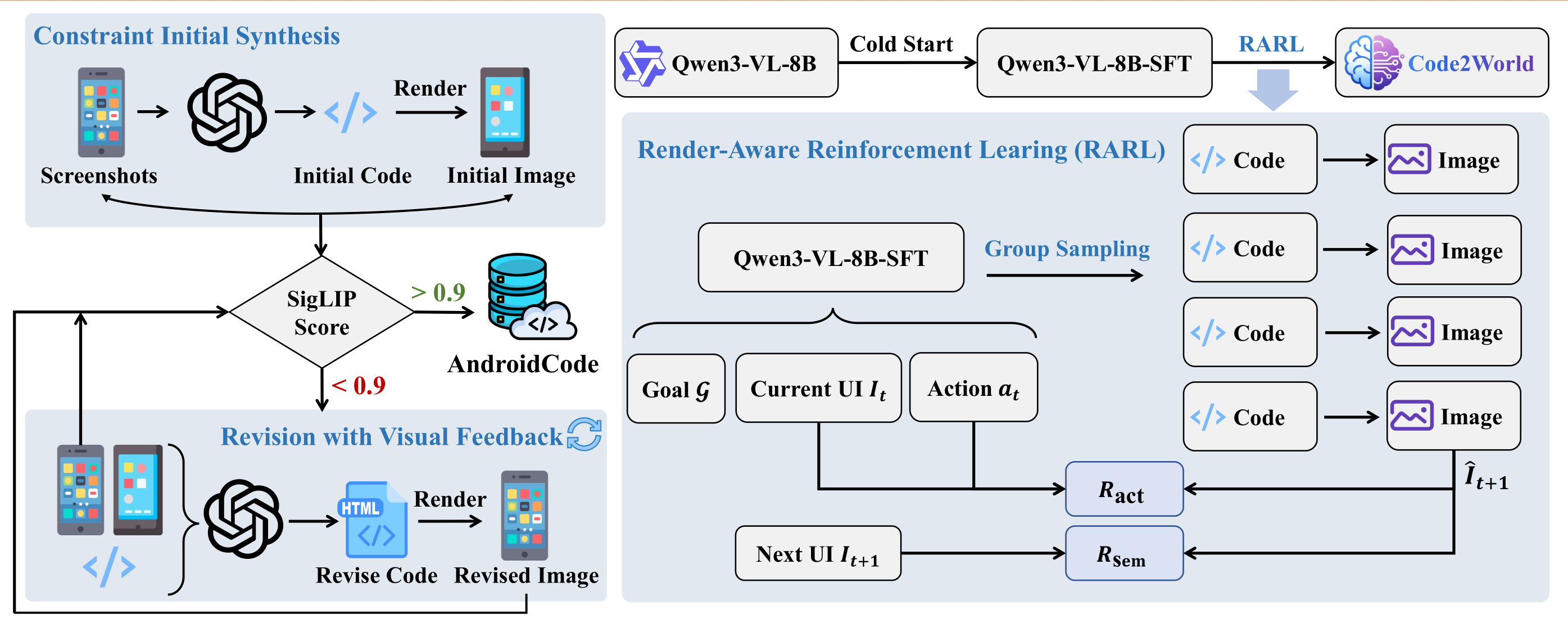{kind=link}
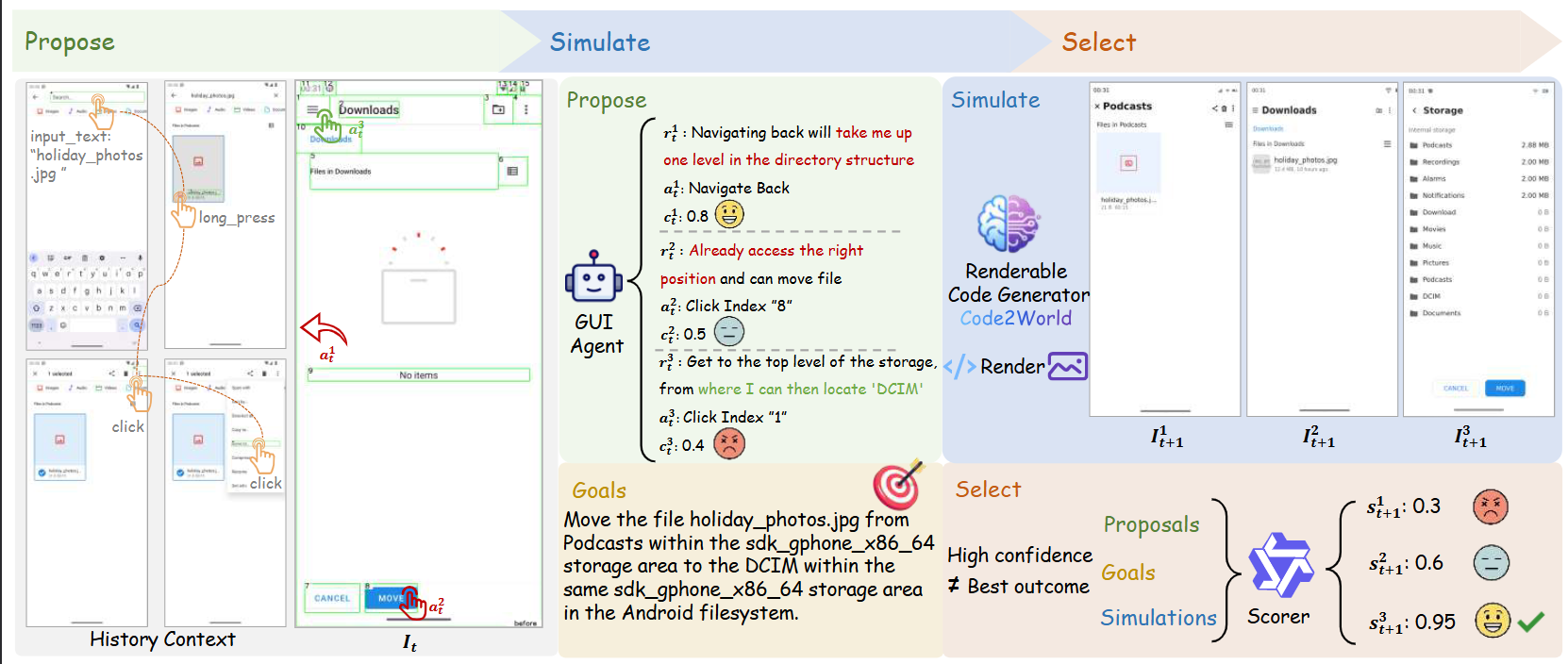{kind=link}
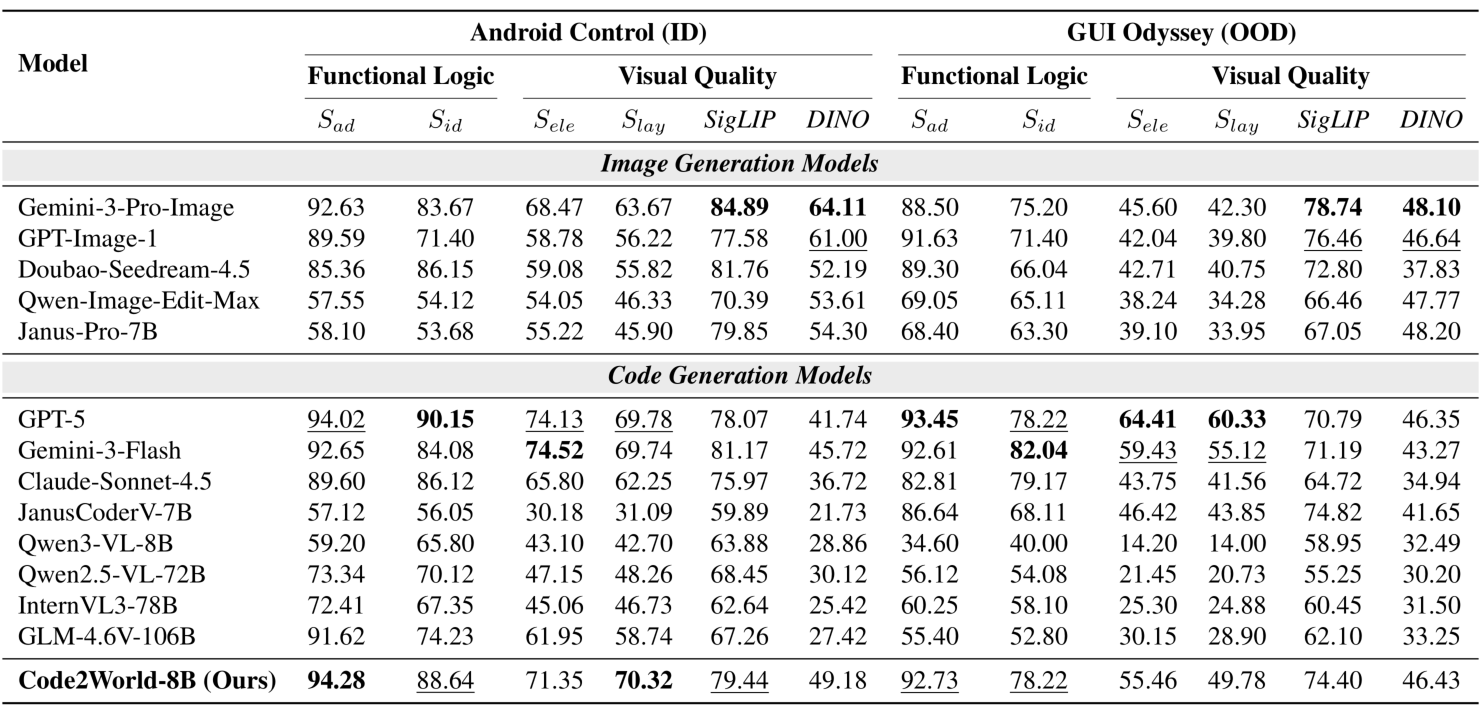{kind=link}
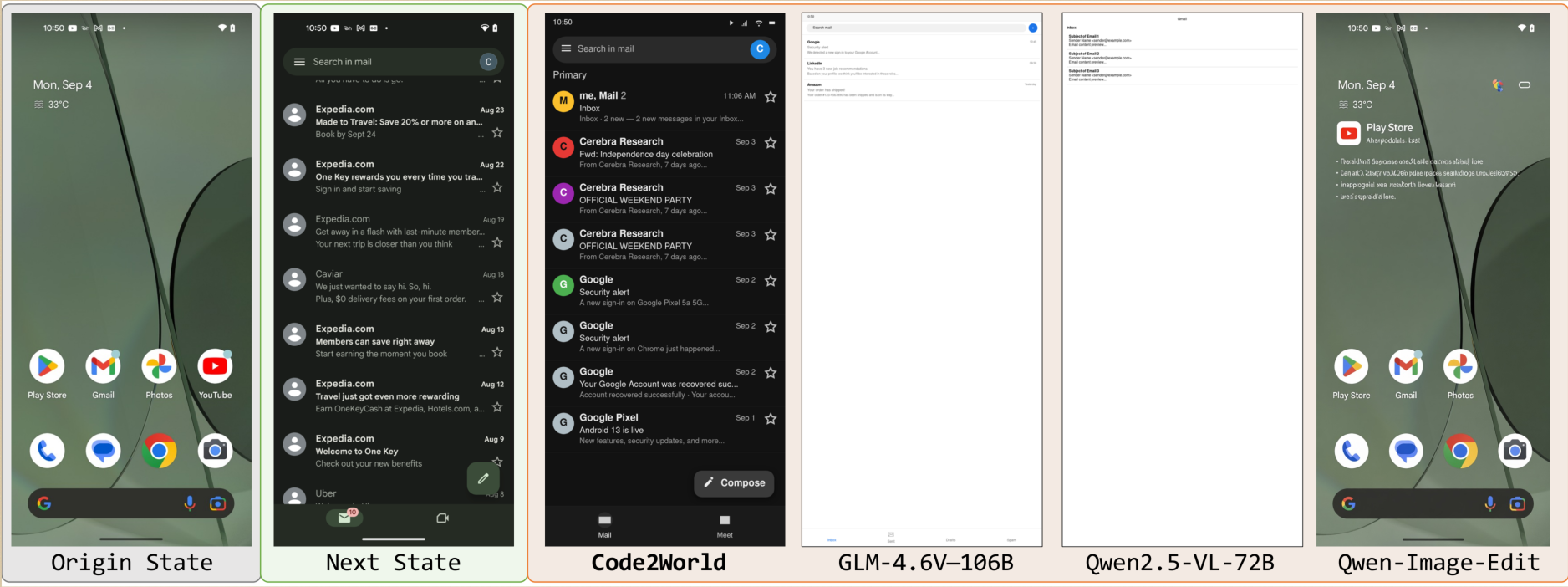{kind=link}
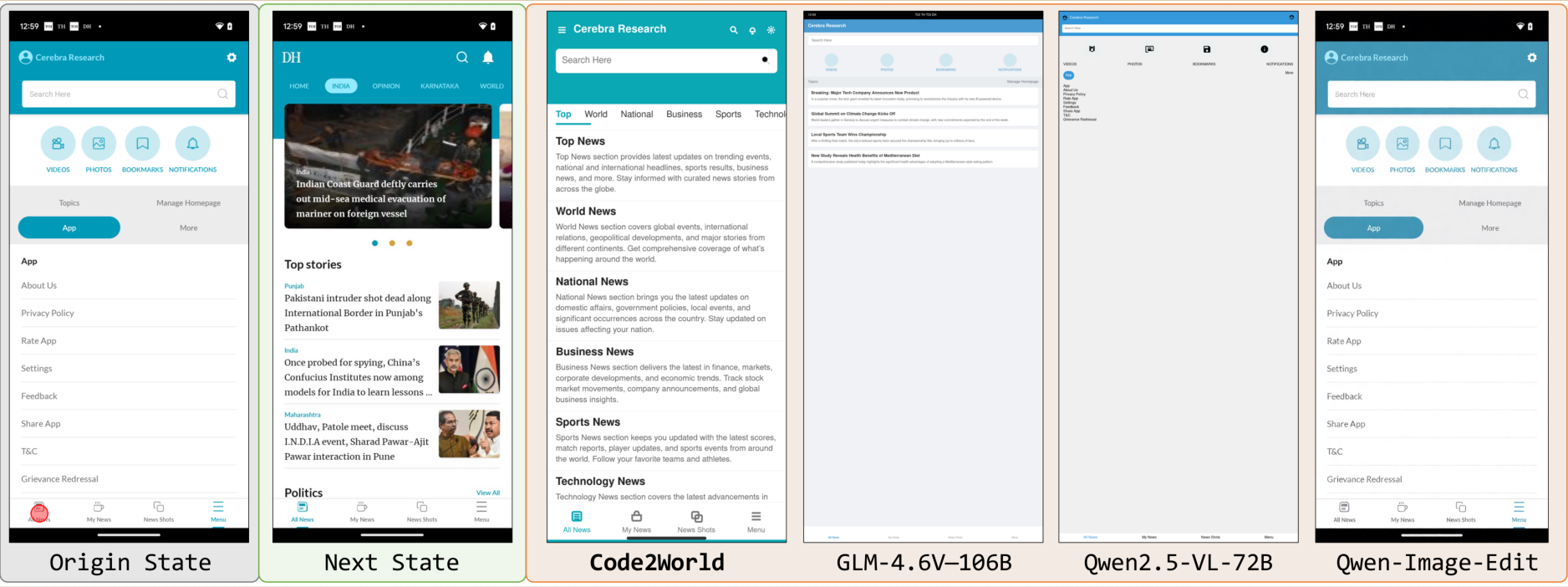{kind=link}
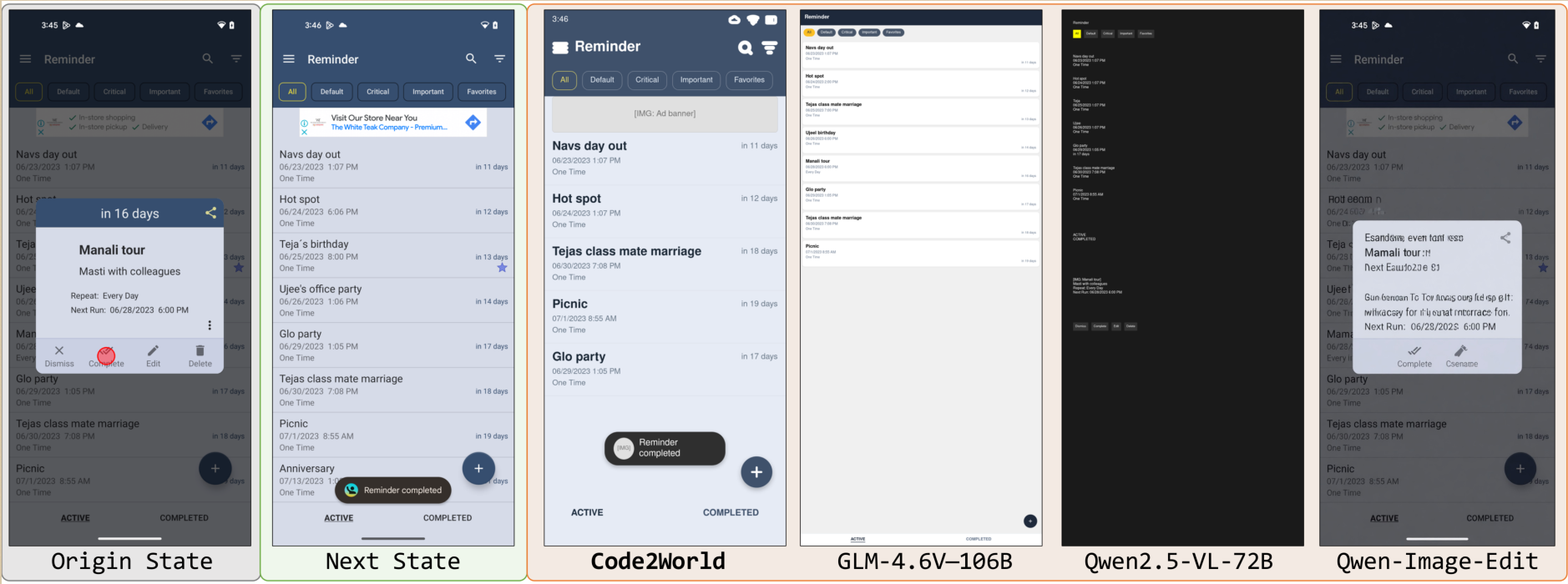{kind=link}
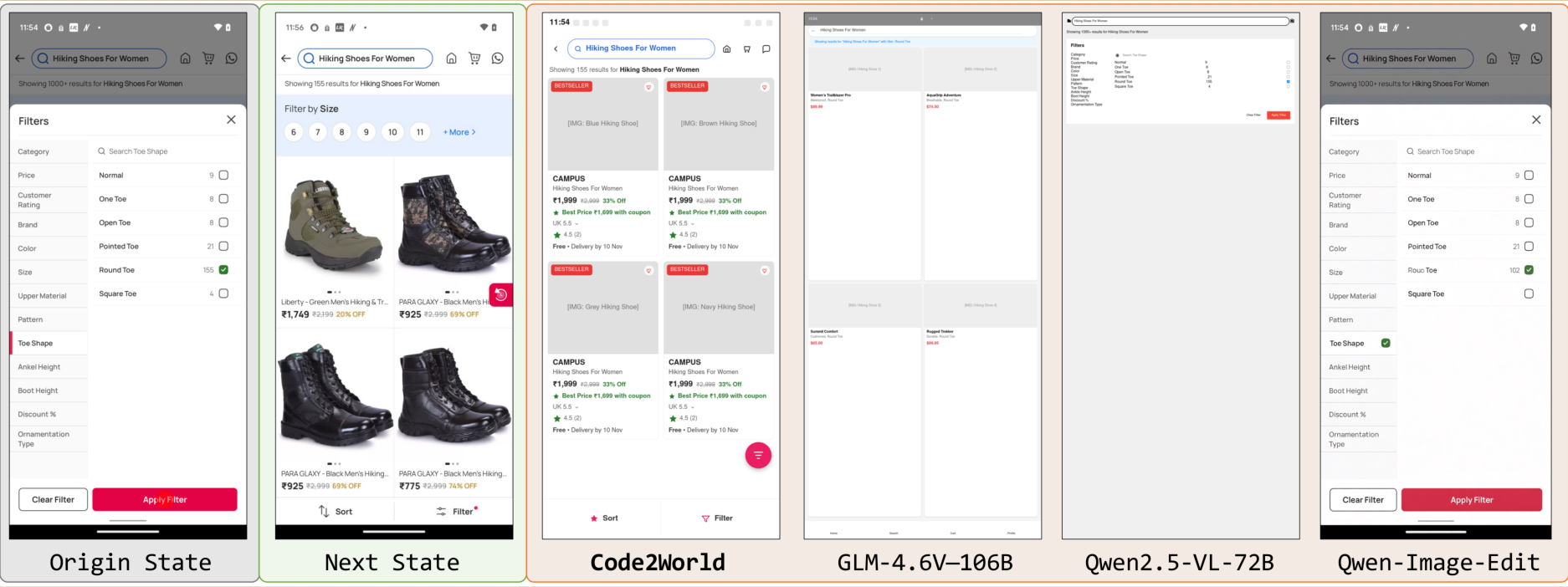{kind=link}
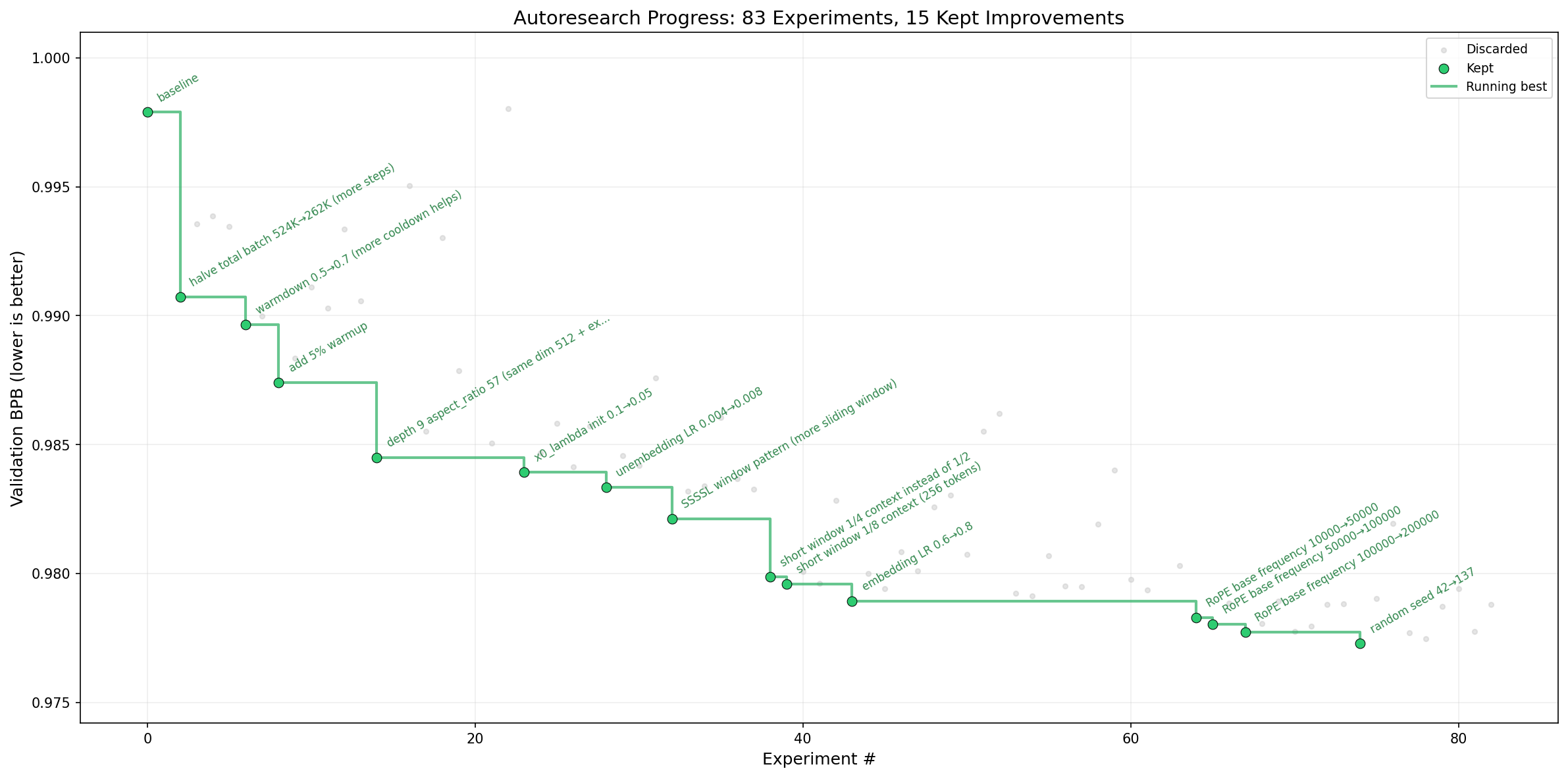{kind=link}
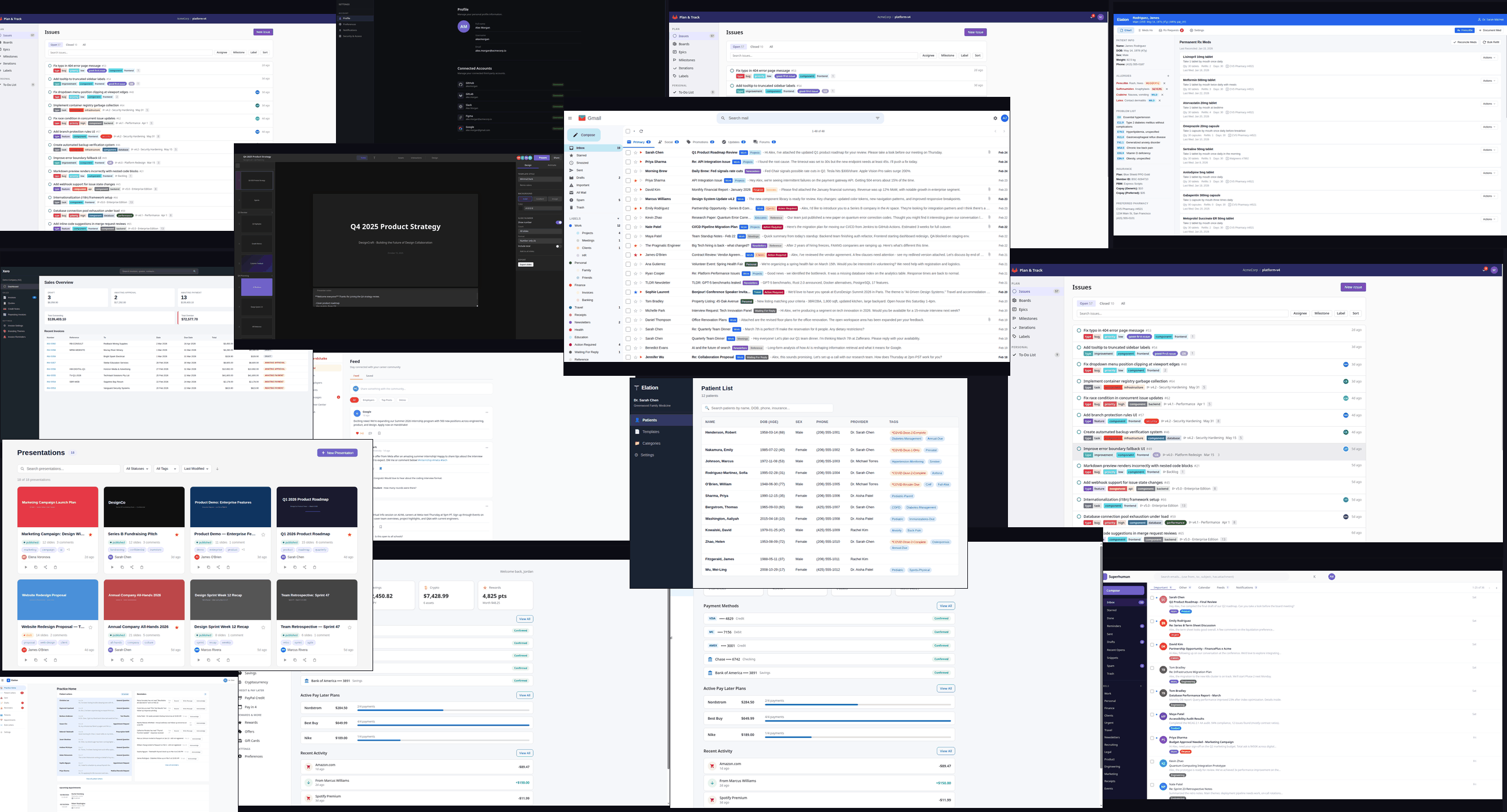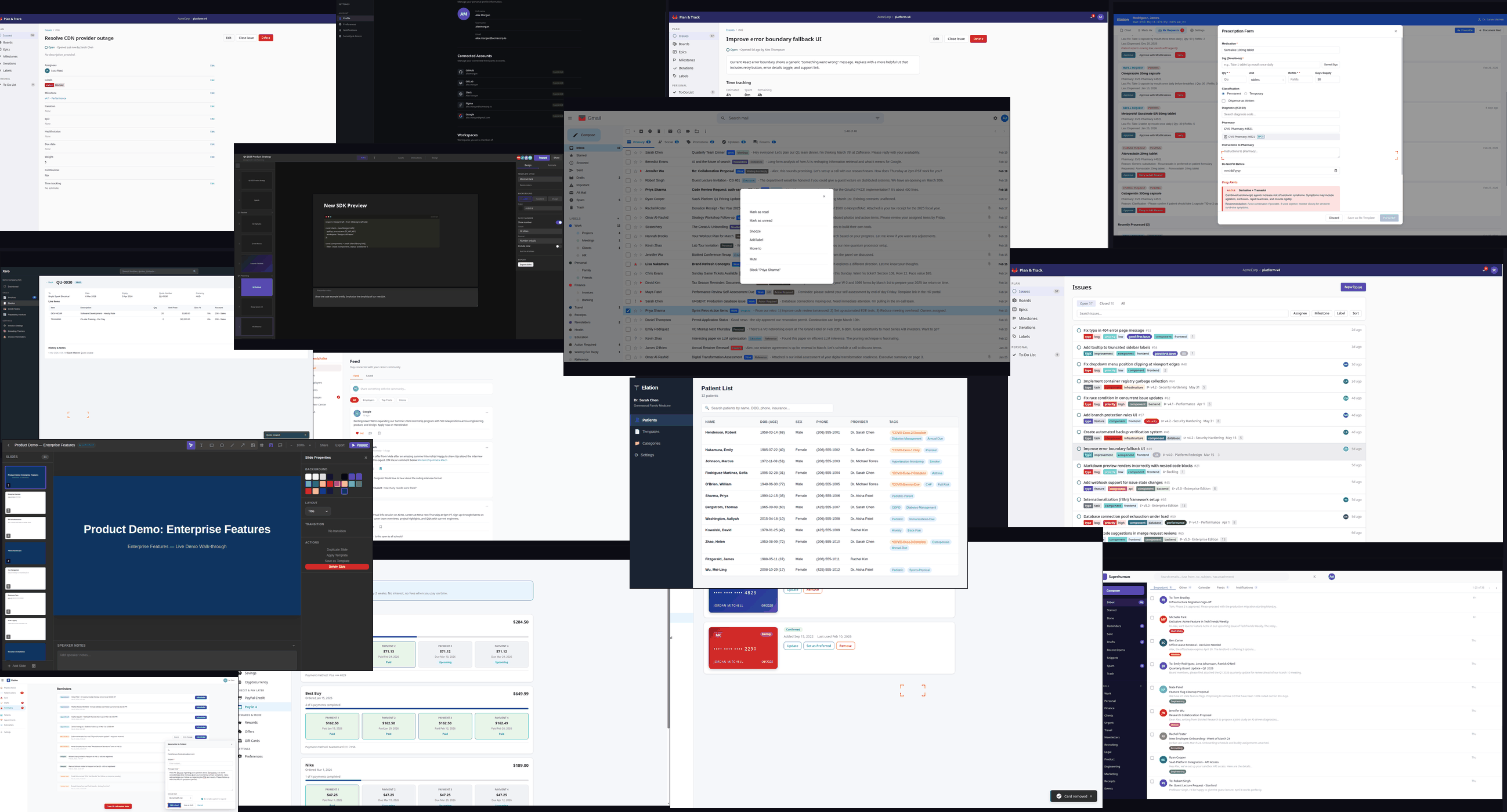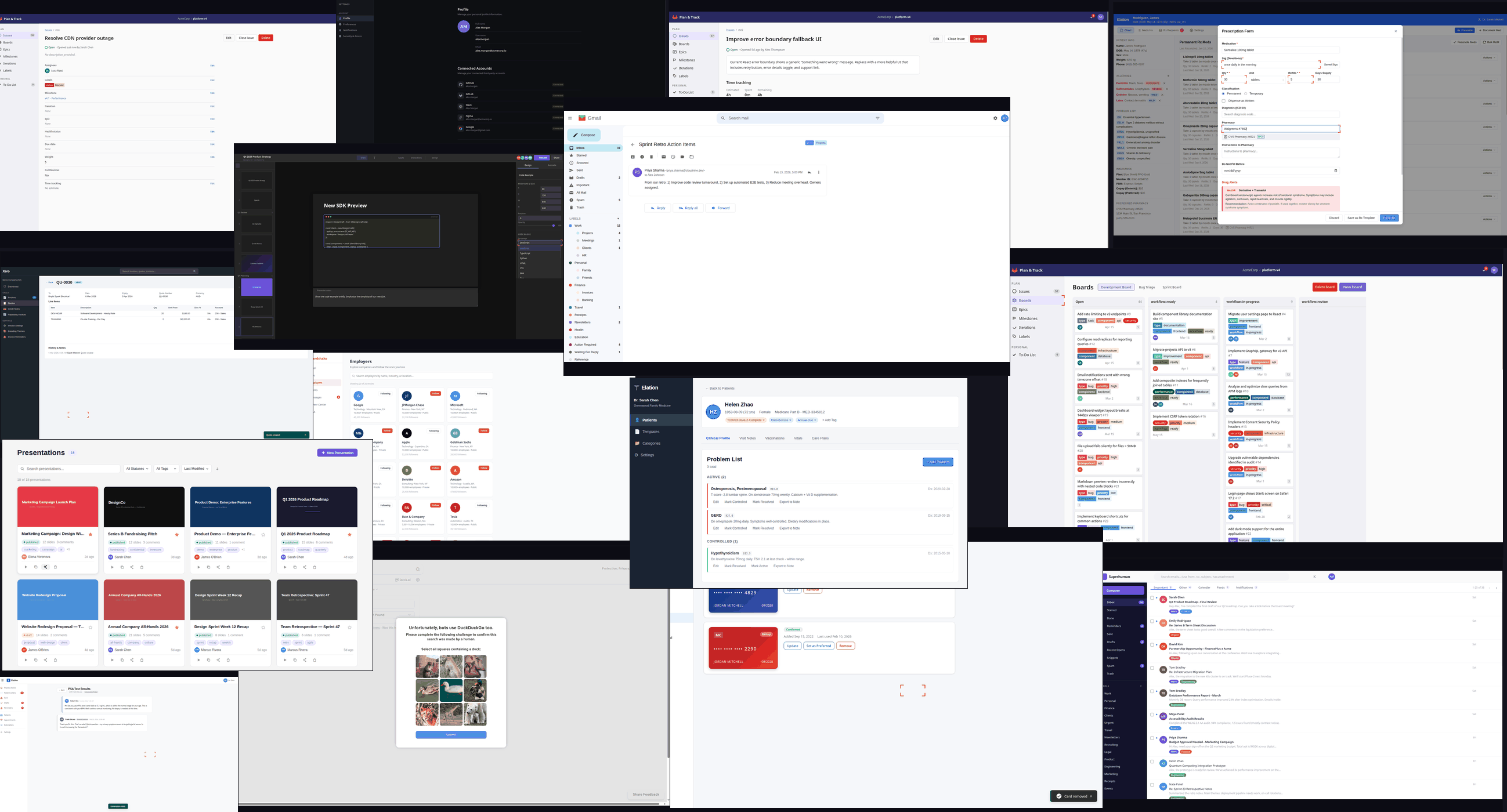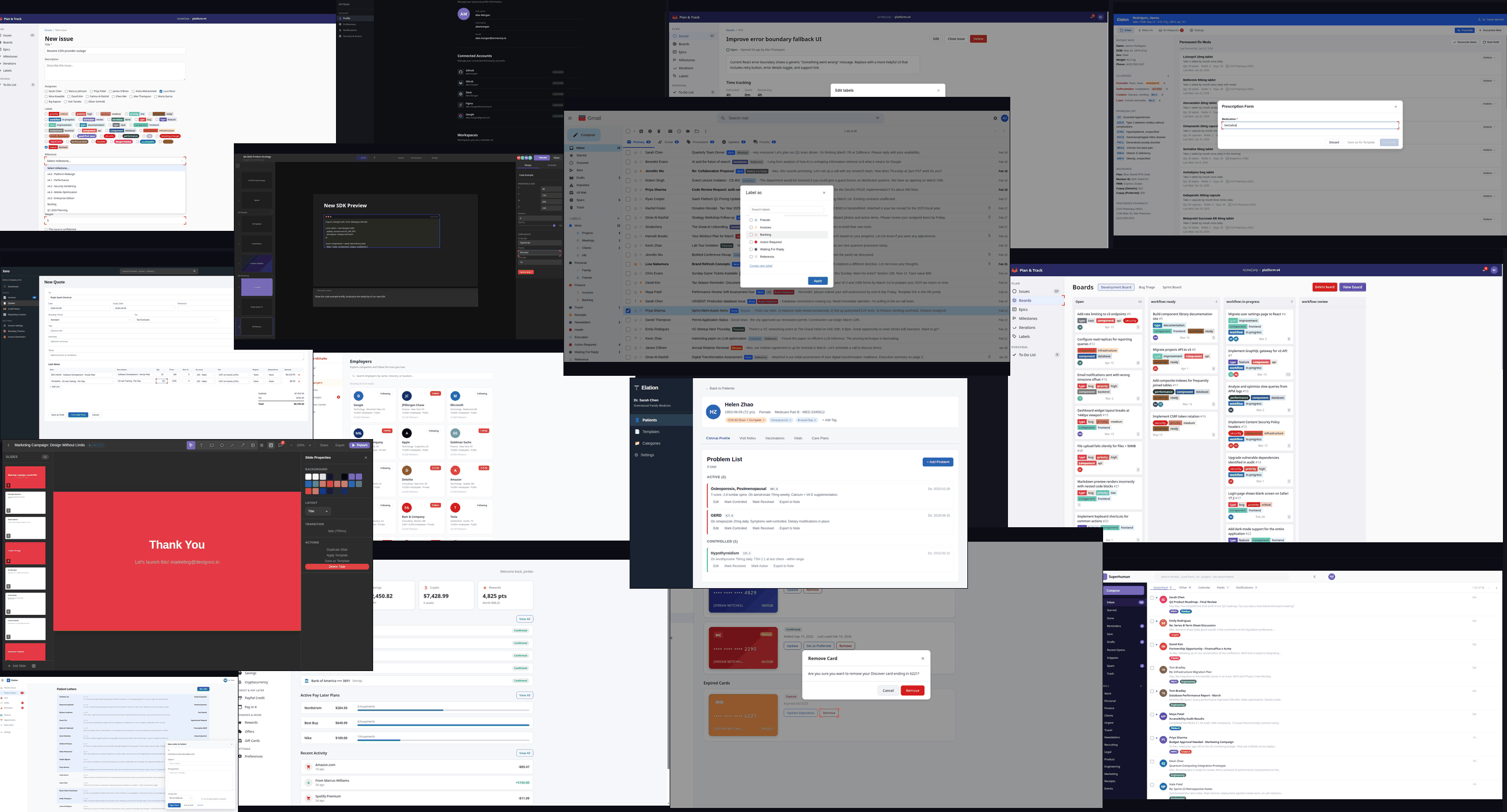{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
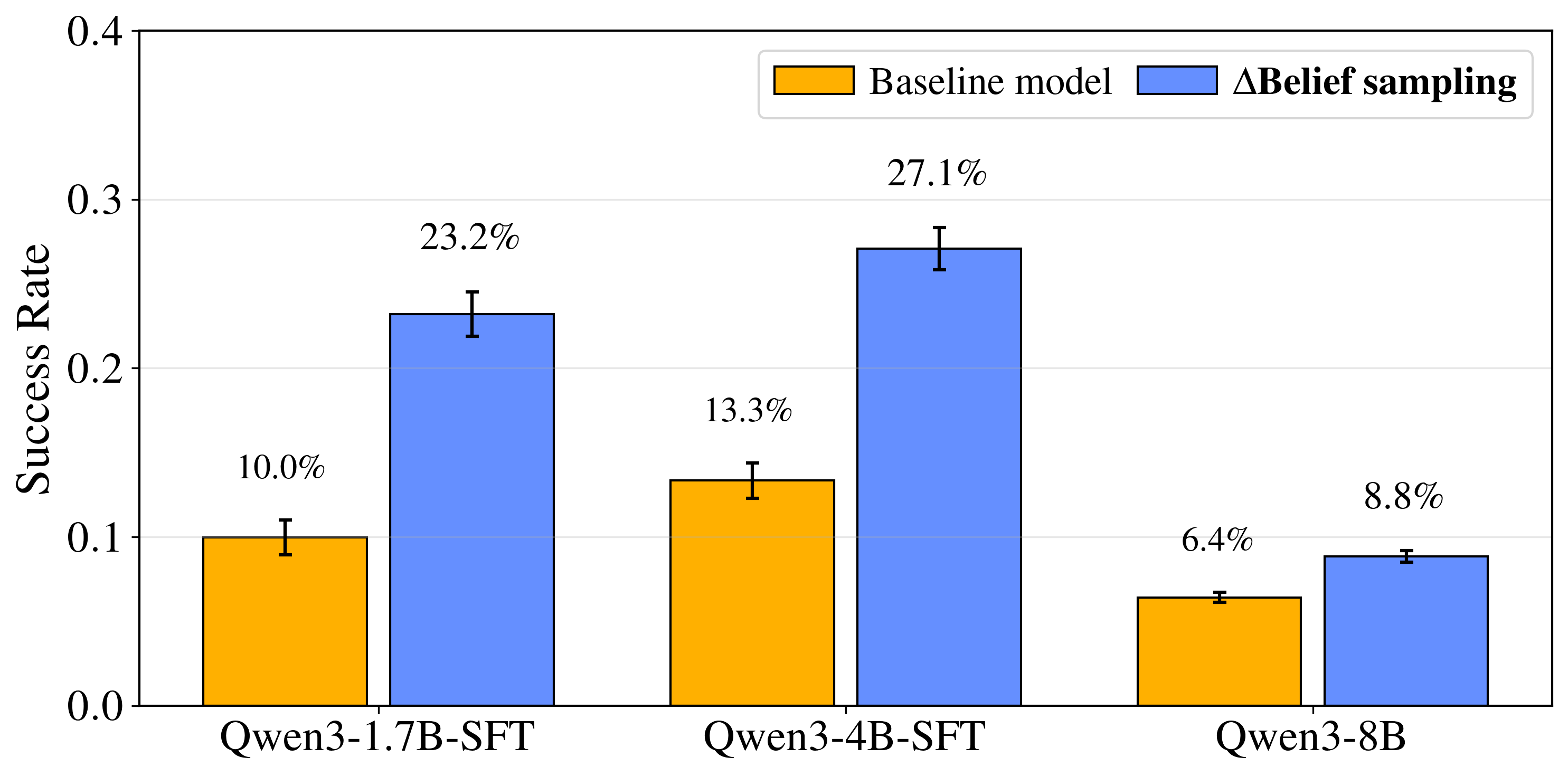{kind=link}
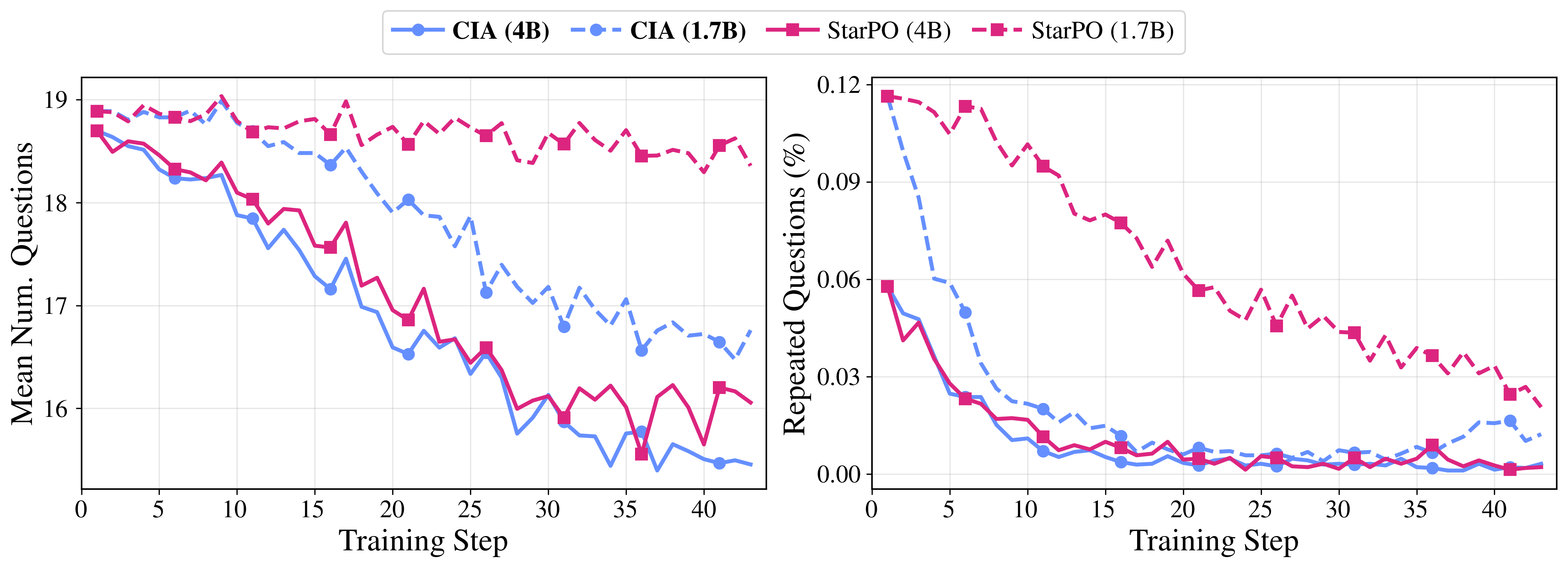{kind=link}
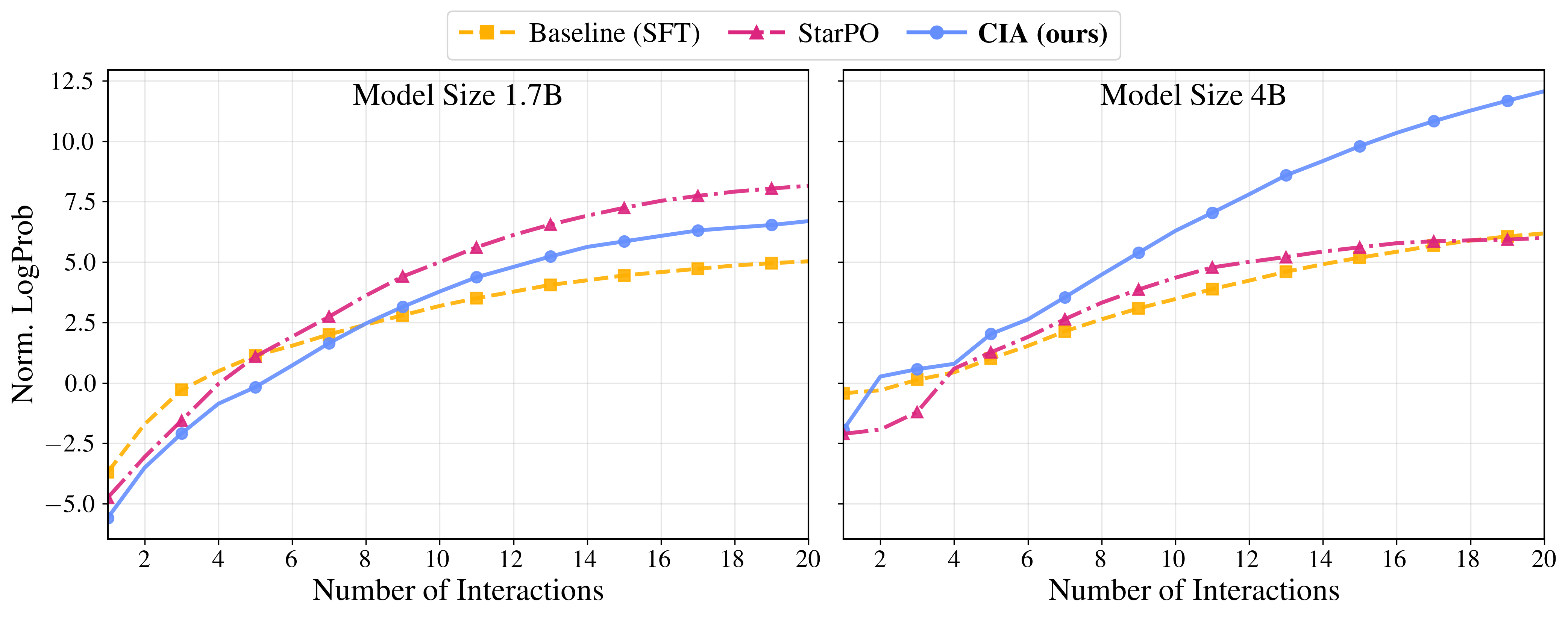{kind=link}
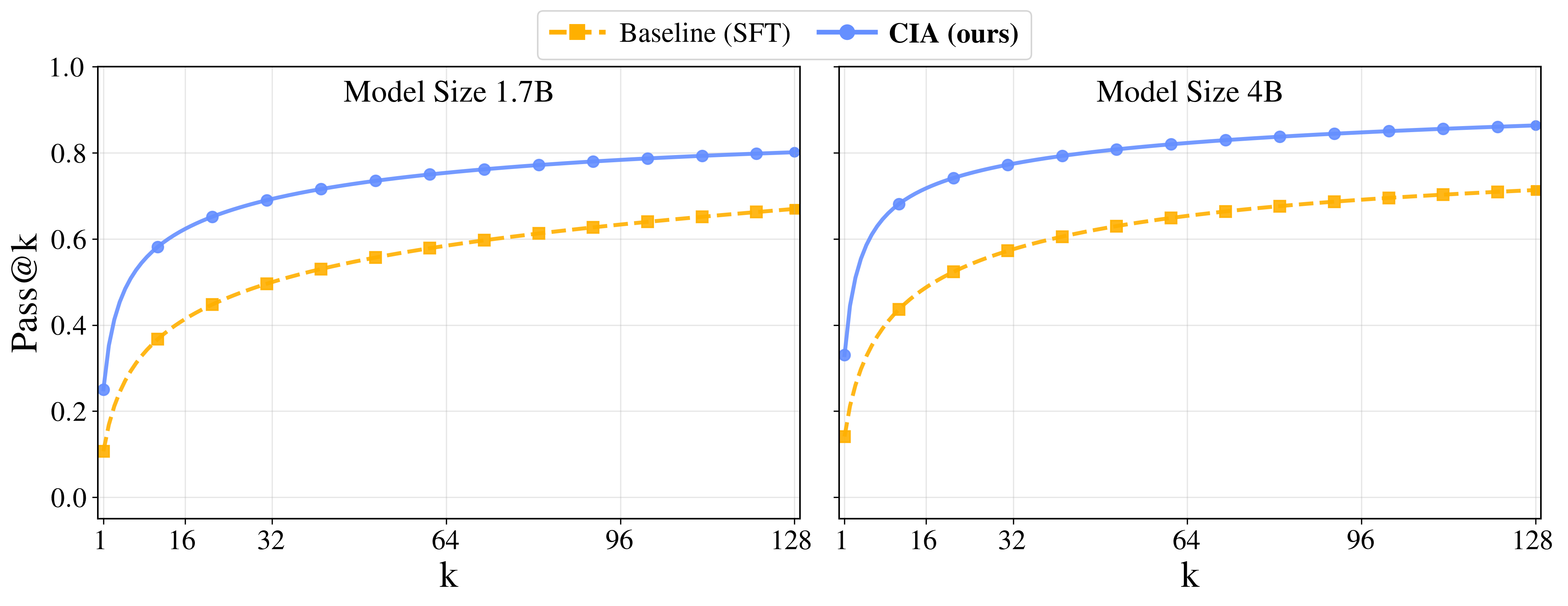{kind=link}
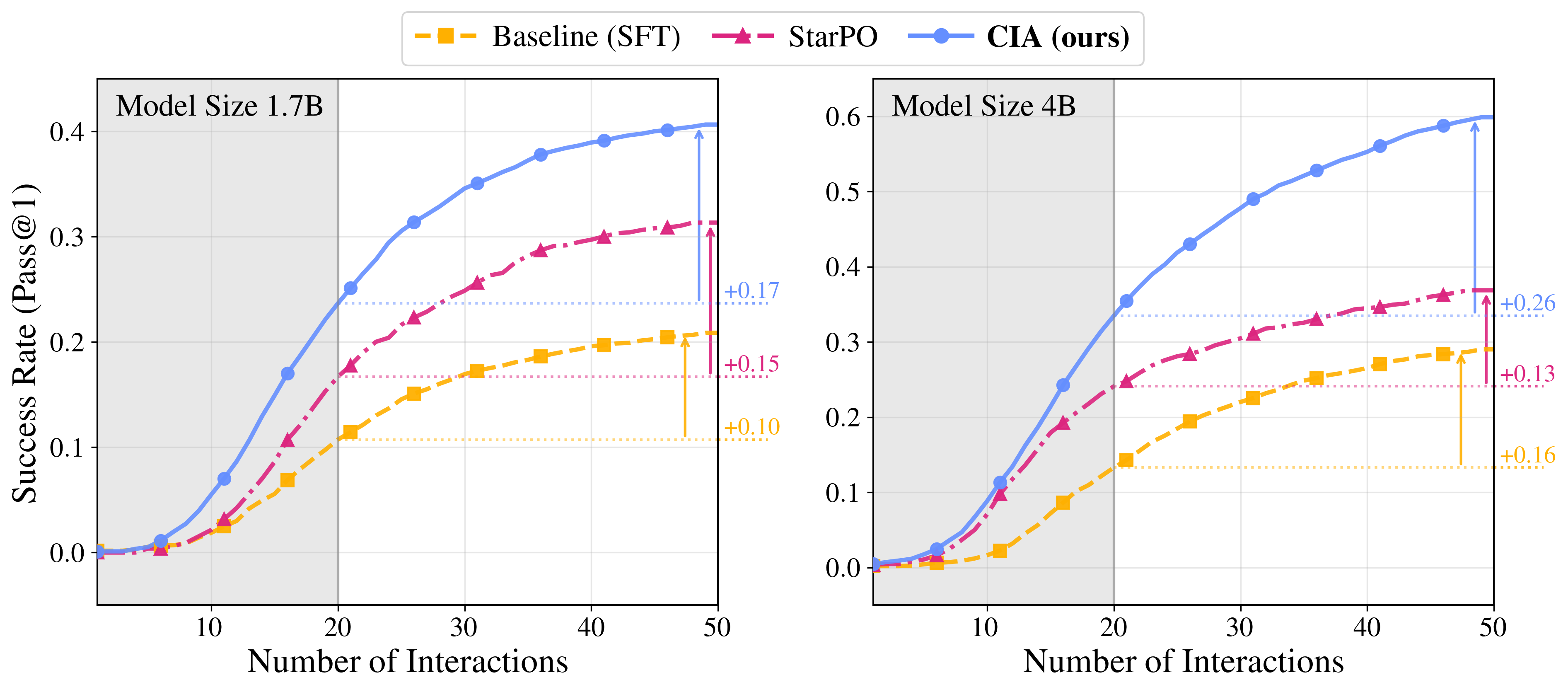{kind=link}
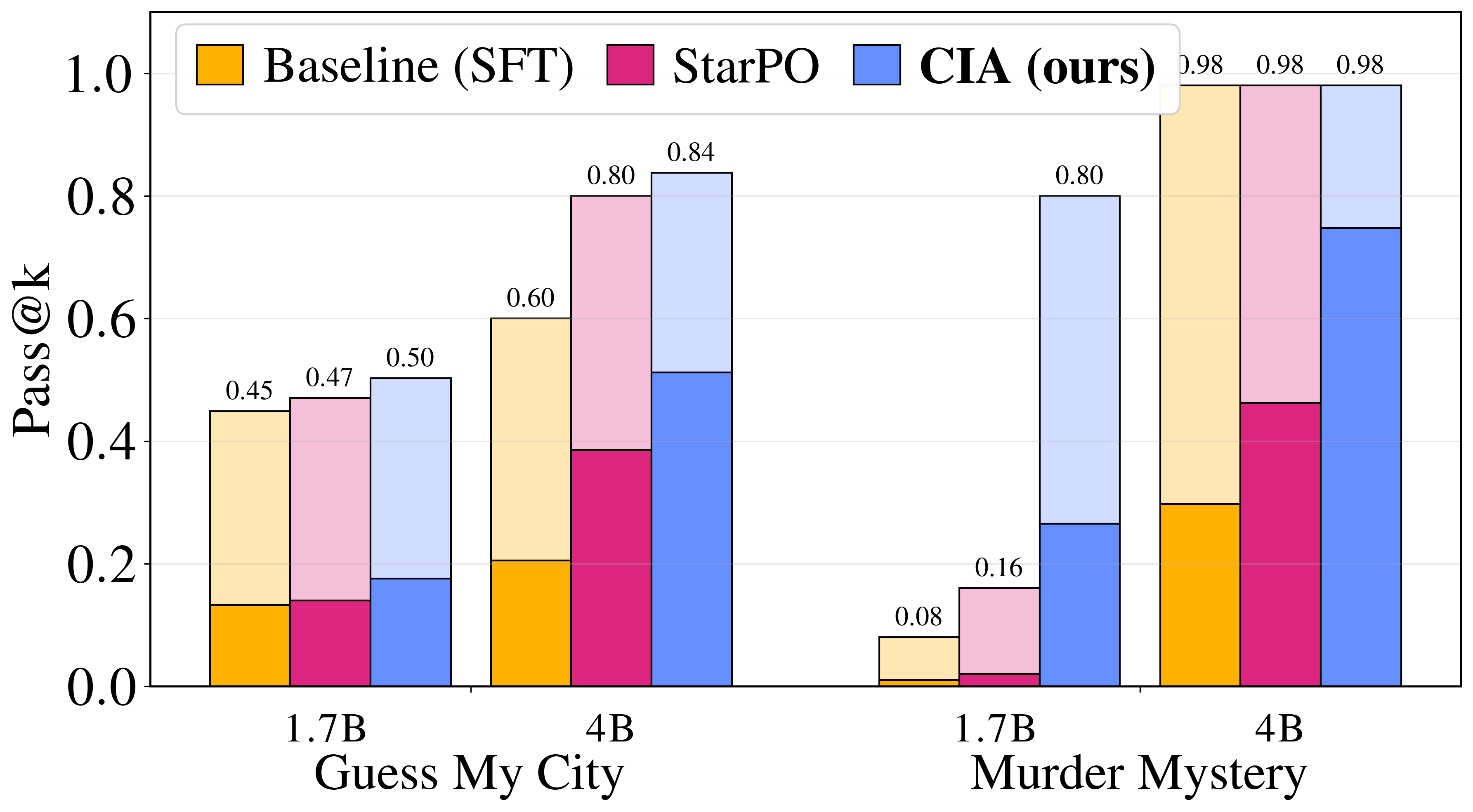{kind=link}
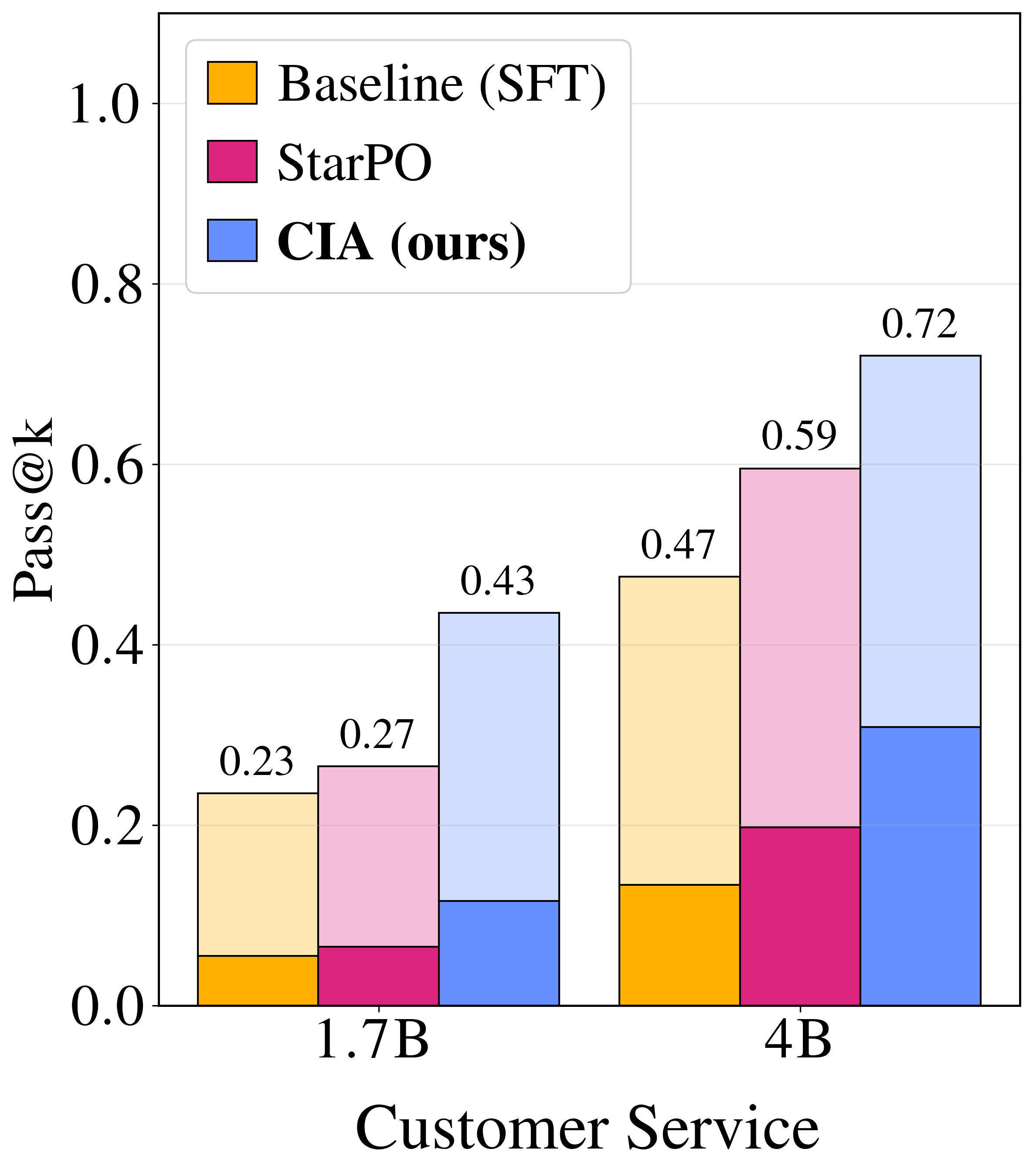{kind=link}
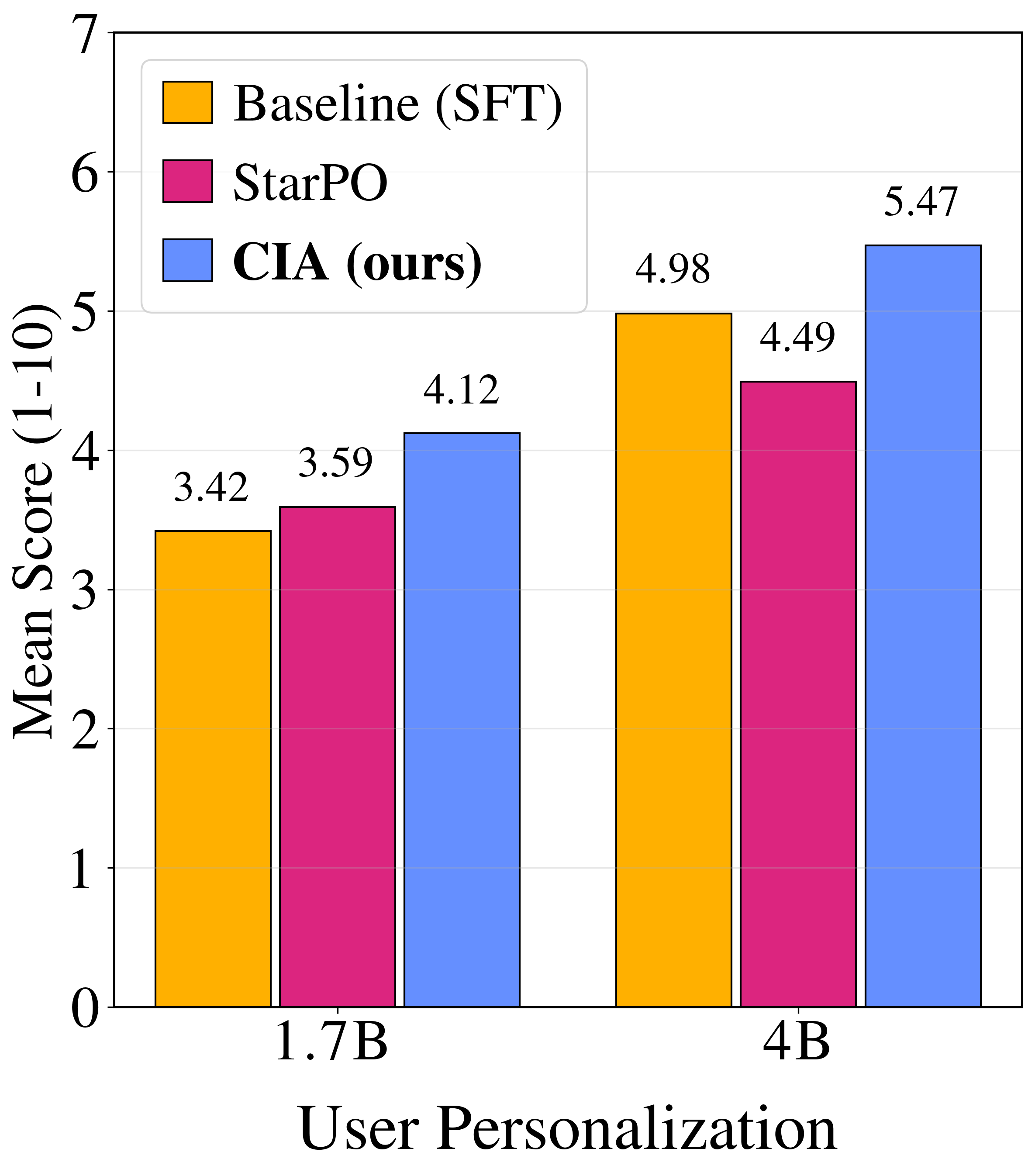{kind=link}
{kind=link}