title: "Agentization of Digital Assets for the Agentic Web: Concepts, Techniques, and Benchmark" url: "https://arxiv.org/html/2604.04226" date: "2026-01-07" author: "" tags: ["agentic-web", "A2A", "agentization", "benchmark", "multi-agent", "digital-assets", "MCP"] ingested: "2026-04-10T12:07:46.277Z"
Linyao Chen2,†, Bo Huang1,4,†, Qinlao Zhao3,†, Shuai Shao1, Zhi Han1, Zicai Cui1, Ziheng Zhang5, Guangtao Zeng6, Wenzheng Tang7, Yikun Wang4,8, Yuanjian Zhou4, Zimian Peng4,9, Yong Yu1, Weiwen Liu1, Hiroki Kobayashi2, Weinan Zhang1,4,∗
1 Shanghai Jiao Tong University 2 The University of Tokyo
3 Huazhong University of Science and Technology 4 Shanghai Innovation Institute
5 Nankai University 6 Singapore University of Technology and Design
7 Queen’s University 8 Fudan University 9 Zhejiang University
† These authors contributed equally to this work.
∗ Corresponding author: wnzhang@sjtu.edu.cn
Abstract
Agentic Web, as a new paradigm that redefines the internet through autonomous, goal-driven interactions, plays an important role in group intelligence. As the foundational semantic primitives of the Agentic Web, digital assets encapsulate interactive web elements into agents, which expand the capacities and coverage of agents in agentic web. The lack of automated methodologies for agent generation limits the wider usage of digital assets and the advancement of the Agentic Web. In this paper, we first formalize these challenges by strictly defining the A2A-Agentization process, decomposing it into critical stages and identifying key technical hurdles on top of the A2A protocol. Based on this framework, we develop an Agentization Agent to agentize digital assets for the Agentic Web. To rigorously evaluate this capability, we propose A2A-Agentization Bench, the first benchmark explicitly designed to evaluate agentization quality in terms of fidelity and interoperability. Our experiments demonstrate that our approach effectively activates the functional capabilities of digital assets and enables interoperable A2A multi-agent collaboration. We believe this work will further facilitate scalable and standardized integration of digital assets into the Agentic Web ecosystem.
1 Introduction
With the rapid development of Large Language Models (LLMs) [achiam2023gpt, zhang2024tinyllama], LLM-based agents [yao2022react, schick2023toolformer] have demonstrated remarkable progress in planning [yao2023treethoughts, wang2023voyager], tool use [schick2023toolformer, liu2025toolace], and interactive decision-making across a wide range of domains [deng2023mind2web, wang2025geovista, crab]. In recent years, LLM-based multi-agent systems (LaMas) [guo2024large, li2024survey, zhang2025avengers] have attracted increasing attention from the research community, emerging as an effective paradigm for real-world AI applications. The Agentic Web [yang2025agentic, guo2025betaweb, zhang2025ufo] is envisioned as the foundational infrastructure for such systems, enabling a decentralized ecosystem in which autonomous agents interconnect and collaborate to solve complex tasks [li2023camel]. Supported by interoperability standards such as the Agent-to-Agent (A2A) protocol [a2a_intro] and the Model Context Protocol (MCP) [mcp-intro], this paradigm aims to maximize large-scale collaboration among heterogeneous agents.
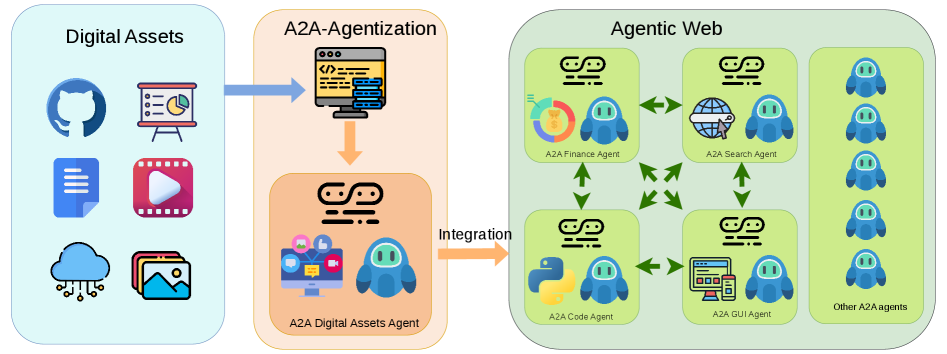
Figure 1: Conceptual illustration of agentization of digital assets for the Agentic Web. Through agentization, digital assets are transformed into A2A-compliant agents that can be integrated into the Agentic Web, enabling interactions and collaborations for real-world tasks.
As observed in prior work [kim2025towards, yang2026understanding], the overall performance of LaMas and Agentic Web is largely determined by the capacity and the scope of agents in the ecosystem, while the scaling of agents will lead to a scaling up of agentic performance in Agentic Web. However, today’s Agentic Web still lacks a scalable way to continuously supply domain-specialized agents, since manual construction is costly, slow, and difficult to scale the diversity.
We argue that existing digital assets provide a natural foundation for addressing this bottleneck. Across the traditional web, digital assets already serve as the primary carriers of knowledge and functionality in a wide variety of domains. They are abundant, diverse, and often already encode valuable domain-specific capabilities. If these assets could be systematically transformed into interoperable agents, they would offer a scalable source of specialized capabilities for the Agentic Web.
In this work, we use the term digital assets to broadly refer to any kind of data is in binary form that stored digitally [toygar2013new], such as code repositories, documents, spreadsheets, images, videos, audio, and online services. In practice, these assets often embody valuable knowledge, functionality, or domain-specific capabilities. As a result, they frequently carry economic, functional, or personal value to their owners [banta2016property, toygar2013new], which in turn creates incentives to make them accessible and usable in the agent ecosystem, thereby unlocking new utility and economic value through interactions with other agents. This motivates the problem we study: how can existing static digital assets be automatically transformed into agents that are compatible with the Agentic Web and can be reliably invoked by other agents?
Realizing automated agentization of digital assets is a non-trivial and challenging task. Automated agentization must overcome three technical hurdles: (1) Inconsistent environments: dependencies often conflict and are hard to reproduce; (2) Unstructured skills: useful capabilities are hidden in undocumented code and must be extracted into atomic, reusable actions; and (3) Semantic gap: even if the code runs, it still needs clear, discoverable interfaces (e.g., agent cards) so others can understand and invoke it. These three challenges are particularly pronounced in code repositories. Therefore, compared with other digital assets, such as documents, services, and audio assets, we adopt code repositories as the representative setting, since they encapsulate the core complexity of the problem and constitute one of the most challenging asset types in practice.
In this work, we propose agentization of digital assets for the Agentic Web, a rigorously defined and fully automated process aimed at dismantling data islands and scaling the agent ecosystem. As illustrated in Figure 1, our approach systematically converts digital assets into agents that are compliant with Agentic Web standards and interoperable under the A2A protocol. To execute this process, we introduce the A2A-Agentization Agent, an autonomous framework specifically designed to resolve environment inconsistencies, extract unstructured skills, and bridge the semantic gap, thereby seamlessly transforming raw repositories into fully functional agents.
To objectively assess progress in this direction, we introduce A2A-Agentization Bench, the first comprehensive benchmark designed to evaluate the full agentization lifecycle of digital assets. Considering the characteristics of digital assets, we ground this benchmark in real-world code repositories, which represent some of the most challenging assets due to their heterogeneous file formats, complex dependency structures, and the need for autonomous exploration and capability verification. A2A-Agentization Bench curates 35 diverse repositories with 522 evaluation instances. Specifically, the benchmark evaluates agentization quality across two critical dimensions: fidelity (the accurate execution of extracted skills) and interoperability (the ability to be seamlessly invoked by other agents). Through this benchmark, we provide a rigorous evaluation of existing methods, identify critical gaps in current approaches, and analyze their strengths and limitations in Section 5.3.
To summarize, our main contributions are as follows:
•
We introduce the concept of agentization of digital assets for the Agentic Web and formalize it in the representative setting of real-world code repositories. Under this setting, we specify the requirements for A2A-compliant agentization and formulate it as a repository-level autonomous development task. Based on this formulation, we propose the A2A-Agentization Agent, which systematically transforms repositories into interoperable agents.
•
We propose A2A-Agentization Bench, the first benchmark specifically designed to evaluate agentization methods of digital assets for the Agentic Web. Grounded in real-world code repositories, the benchmark provides a systematic assessment of whether automated methods can reliably produce interoperable, A2A-compliant agents.
•
We demonstrate the effectiveness of the A2A-Agentization Agent on A2A-Agentization Bench by integrating it with representative state-of-the-art agent frameworks. Our results reveal that, while automated agentization is feasible, current methods still face substantial challenges, highlighting key bottlenecks in reliable agent production.
2 Related Work
2.1 Repository Utilization Benchmark
Repository utilization marks a shift in code agents from generating isolated scripts to interacting with real-world engineering systems, with benchmarks diverging into two streams. The first stream, repository development, evaluates agents on maintaining or extending codebase logic. RepoBench [liu2023repobench] introduces live evaluation for repository-level code completion, focusing on cross-file context. Similarly, DevEval [li2024deveval] and EvoCodeBench [li2024evocodebench] align with real-world repository distributions to assess generation fidelity and dependency understanding.
The second stream, task-solving, treats the repository as an executable resource for end-to-end problem solving. SWE-bench [jimenez2023swe] pioneered the issue-patch-test loop to verify bug fixes, while GitTaskBench [ni2026gittaskbench] binds tasks to specific repositories to test workflow automation. To address specific bottlenecks, EnvBench [eliseeva2025envbench] targets the critical environment setup phase, and LoCoBench [qiu2025locobench] evaluates long-context reasoning for complex engineering tasks. While these works focus on consuming repositories for tasks, our work uniquely evaluates the agentization process itself: transforming code repo into standardized, A2A-compliant agents for the Agentic Web.
2.2 Agentization Methods
As a process of generating agents, agentization [park2023generative, chen2024autoagents] refers to endowing static digital assets with autonomous capabilities. Early works [qin2023toolllm, liang2024taskmatrix, wolflein2025llm] focused on transforming existing services into tools, thereby bridging rigid interfaces with LLM flexibility. Similarly, works [wolflein2025llm, lin2025autop2c] are devoted to transforming the digital assets into tools, thereby enhancing agent capabilities. Furthermore, several works focus on directly transforming the digital assets into agents. Paper2Agent [miao2025paper2agent] transforms scientific research papers into interactive agents via setting up the operation environment and building the paper as an MCP server via a well-defined multi-agent system, while repomaster [wang2025repomaster] explores the research on generating corresponding agents for code repositories. EnvX [chen2025envx] advances agentization research by transforming repositories into executable agents. While these works advance agentization, they do not ensure Agentic-Web-compatible communication, which limits the wider usage of generated agents. Our work addresses this gap through a standardized pipeline for repository agentization with strict A2A compliance.
2.3 Protocols for LLM-based Agents
Standardized protocols are essential for the scalability of the Agentic Web. Early systems relied on framework-specific interfaces, limiting cross-ecosystem collaboration [park2023generative, wu2024autogen, hong2023metagpt]. More recently, standards such as the Model Context Protocol (MCP) and Agent-to-Agent (A2A) protocol have emerged to support structured tool use and decentralized agent interaction [mcp-intro, a2a_intro, yang2025survey].
Despite this progress, existing research has predominantly focused on evaluating how effectively agents utilize available protocol-compliant tools [wang2025mcp, lei2025mcpverse, yan2025mcpworld]. In contrast, relatively little attention has been paid to how such tools and services are constructed or adapted to conform to protocol specifications, particularly when transforming legacy software into agent-compatible components.
3 Methodology
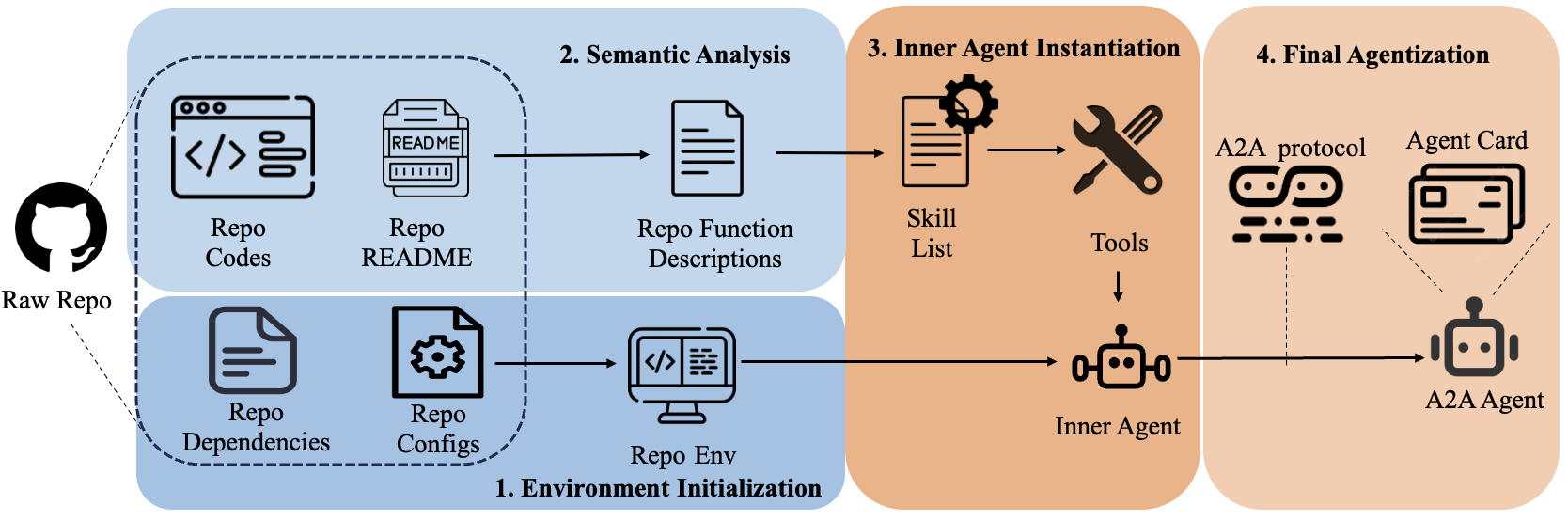
Figure 2: Processing pipeline of repository agentization. The repository agentization process starts from raw repository contents and is organized into four stages. The agent first initializes the repository environment, then analyzes repository contents to extract skills, instantiates an inner agent, and finally produces an A2A-compliant agent with an agent card.
In this section, we introduce how we agentize digital assets and link generated agents into Agentic Web. We introduce some preliminaries and detailed definitions in section 3.1, and present the agentization process along with its practical implementation, Agentization Agent in section 3.2.
3.1 Preliminaries and Definition of Agentization for Agentic Web
The goal of agentization is to transform a static Digital Asset (𝒟\mathcal{D}) into a compliant, interactive agent (𝒜\mathcal{A}) within the Agentic Web ecosystem. Here the 𝒜\mathcal{A} is required to be compliant to A2A protocol to ensure the communication within Agentic Web.
In this work, as introduced in section 1, we specifically focus on agentizing and benchmarking Code Repositories (𝒟repo\mathcal{D}_{repo}), which serve as a complex class of digital assets containing functional logic. We define the context of code repositories as a set of workspace components (𝒲\mathcal{W}):
𝒟repo={𝒲dep,𝒲conf,𝒲codes,𝒲readme},\mathcal{D}_{repo}=\{\mathcal{W}_{dep},\mathcal{W}_{conf},\mathcal{W}_{codes},\mathcal{W}_{readme}\},
(1)
where 𝒲dep\mathcal{W}_{dep} denotes the package dependencies of given repositories, 𝒲conf\mathcal{W}_{conf} denotes the configs of given repositories, 𝒲codes\mathcal{W}_{codes} denotes the codes of given repositories and 𝒲readme\mathcal{W}_{readme} denotes the readme file of the repositories, which is a key of given tasks.
3.2 Agentization Process
As introduced in Figure 2, we formalize the agentization process as a set of requisite transformations that map 𝒟\mathcal{D} to the components of an A2A-compliant agent. These components serve as the functional requirements for our system. We define the process as four stages.
Environment Setup
The foundation of an executable agent is a reproducible environment, denoted as ℰ\mathcal{E}, consisting of both environment variables and the code environment for running the agent. This mapping ensures that the static logic within the asset can run deterministically:
ℰ=𝒢env(𝒲dep,𝒲conf),\mathcal{E}=\mathcal{G}_{env}(\mathcal{W}_{dep},\mathcal{W}_{conf}),
(2)
where 𝒢env\mathcal{G}_{env} represents the synthesis of configuration settings (e.g., container images) that encapsulate the system-level dependencies and runtimes required by the digital asset.
Skill Extraction as Tools
To grant the agent capabilities, we extract a set of atomic functions 𝒯\mathcal{T} from the asset in this phase. This process relies on the established environment to verify execution:
𝒯=𝒢tool(𝒟repo,ℰ),\mathcal{T}=\mathcal{G}_{tool}(\mathcal{D}_{repo},\mathcal{E}),
(3)
where 𝒢tool\mathcal{G}_{tool} denotes the process of identifying, wrapping, and validating functional units as executable tools from 𝒟\mathcal{D}.
Inner Agent Instantiation
The core cognitive architecture of the agent, denoted as 𝒜in\mathcal{A}_{in}, is constructed by integrating these tools into a reasoning loop (e.g., a ReAct loop [yao2022react]):
𝒜in=𝒢inner(𝒟repo,ℰ,𝒯).\mathcal{A}_{in}=\mathcal{G}_{inner}(\mathcal{D}_{repo},\mathcal{E},\mathcal{T}).
(4)
This step instantiates the agent’s internal logic, enabling it to plan and execute the extracted skills to solve tasks.
Final Agentization
To generate an A2A-compliant agent, the system should generate the agent card 𝒞\mathcal{C} as following equation:
𝒞=𝒢card(𝒟repo,𝒯).\mathcal{C}=\mathcal{G}_{card}(\mathcal{D}_{repo},\mathcal{T}).
(5)
The agent card serves as a self-description registry, detailing the agent’s identity and available tools, enabling other agents to understand its capabilities without internal inspection. And the finalized agent is denoted as
𝒜={𝒜in,𝒞}\mathcal{A}=\{\mathcal{A}_{in},\mathcal{C}\}
(6)
In practice, we operationalize this framework by wrapping the repository into a larger codebase context and formulating the agentization stages as distinct features. We then introduce an Agentization Agent to perform end-to-end repository development. Specifically, this agent executes repository-level feature implementation, thereby converting the static repository into an active agent.
4 A2A-Agentization Benchmark
We introduce the A2A-Agentization Benchmark, a comprehensive dataset and evaluation framework designed to assess the capability of Agentization methods to autonomously transform open-source software repositories into A2A-compliant agents integrated into the Agentic Web, where these agents can directly interact with peer agents.
4.1 Benchmark Construction
The construction of A2A-Agentization Bench follows a systematic pipeline. We first curate a diverse set of repositories and establish ground-truth Agent Skills as the static foundation. Subsequently, we generate execution scenarios at two granularities: Single-Repo and Multi-Repo tasks. These artifacts collectively underpin our dual-dimensional evaluation: Single-Repo tasks specifically enable the Capability Inheritance Assessment, while the Agent Skills annotation and Multi-Repo tasks facilitate the comprehensive Collaborative Execution Assessment.
Repository Collection.
To rigorously assess agent capabilities across the Agentic Web, we curate 35 diverse GitHub repositories (see Appendix B for the full list). Drawing inspiration from recent repository analysis taxonomies [ni2026gittaskbench], we organize these repositories into 9 primary Task Domains to ensure broad coverage of real-world software interactions. Representative domains include: (1) Visual & Video Processing (e.g., Ultralytics, Stable Diffusion); (2) Document & Web Automation (e.g., Unstructured, Trafilatura); and (3) Scientific & Specialized Computing, spanning fields like Computational Chemistry (e.g., ChemFormula) and Quantitative Finance (e.g., Backtrader).
This domain-centric selection captures heterogeneous file formats and cross-file transformation workflows, enabling realistic inter-agent dependencies.
These repositories are standardized with rigorous quality control and protocol-compliant transformations to support the subsequent agentization pipeline.
Agent Skill Annotation.
Rather than manually synthesizing all metadata fields, we focus strictly on establishing the ground truth for Agent Skills—the functional core of the agent. Human experts manually identify and formalize these skills by extracting key functionalities from repository artifacts (e.g., README.md, unit tests). To ensure these skills validly represent the repository’s value, we enforce two annotation criteria: (1) Core Capability Inheritance: The skill must encapsulate a primary, non-trivial feature of the repository (e.g., Image Segmentation for a vision library) rather than a generic utility; (2) Atomic Functional Unit: Each skill should represent a distinct, reusable action that can be invoked independently within an agentic workflow. These expert-annotated skills serve as the gold standard for verifying the specification quality of the generated AgentCard, ensuring the agent uses semantically precise descriptions to be correctly discovered by the orchestrator. In total, we annotate 127 Agent Skills across 35 repositories.
Execution Task Generation.
To evaluate agentization under realistic Agentic Web interactions, we construct execution tasks that are strictly repository-dependent, such that correct solutions must invoke repository-specific APIs or behaviors rather than relying on generic reasoning or external libraries.
We generate tasks using two procedures. For Single-Repo Tasks (see Appendix C.3), a code agent analyzes an individual repository’s documentation, unit tests, and exposed APIs to synthesize tasks whose solutions require invoking internal, repository-specific functions, directly probing intra-agent capability inheritance. For Multi-Repo Tasks (see Appendix C.4), we adopt a two-stage process in which a search agent first identifies semantically complementary repositories, after which the code agent analyzes each repository in isolation and jointly constructs cross-repository workflows. These workflows are formulated as strictly linear dependency chains, where each agent must consume the concrete output of the previous agent as its sole valid input, making every step indispensable.
To ensure task validity and fairness, all generated tasks undergo a verification pipeline. Each task is dry-run in isolated environments to eliminate execution errors, followed by expert human review to confirm semantic meaningfulness and strict dependence on repository-specific capabilities. After verification and filtering, we retain 336 Single-Repo Tasks and 186 Multi-Repo Tasks.
4.2 Execution Task Data Analysis
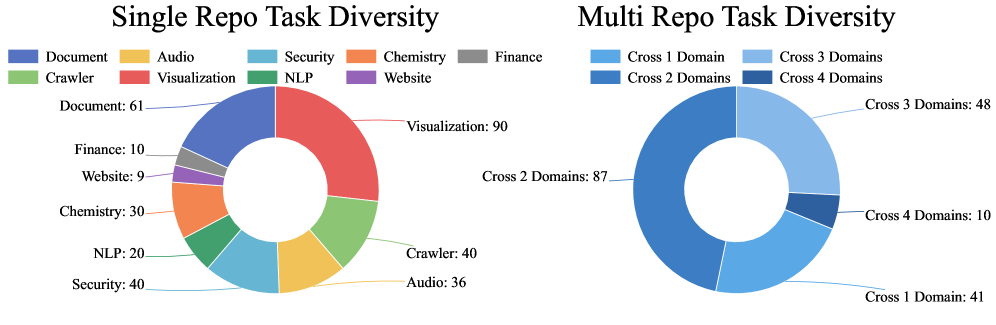
Figure 3: Execution task diversity analysis. Single-repo tasks are distributed across 9 application domains, illustrating broad coverage of domain-specific execution scenarios. Multi-repo tasks are grouped by the number of distinct domains involved in each workflow (cross-kk domains), highlighting the prevalence of cross-domain interactions and increasing interoperability requirements.
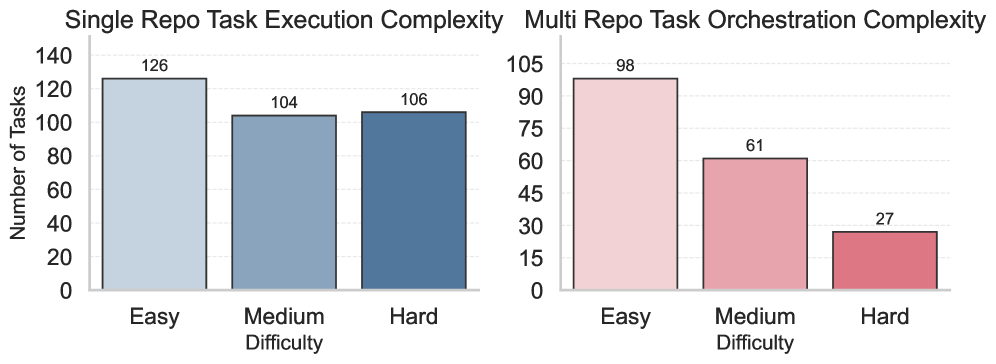
Figure 4: Execution task complexity distribution. For single-repo tasks, difficulty is decomposed into several dimensions , measured by corresponding indicators. For multi-repo tasks, difficulty is determined by orchestration complexity, measured by the length of the linear collaboration chain (i.e., the number of sequentially invoked repositories). Tasks are grouped into easy, medium, and hard tiers based on these respective criteria.
Execution Tasks Diversity.
To ensure that the benchmark captures a representative spectrum of real-world software automation challenges, we analyze the diversity of execution tasks along two complementary dimensions: single-repo domain coverage and multi-repo cross-domain composition.
We introduce the task diversity in figure 3. The left panel of the figure presents the distribution of 336 single-repo tasks across 9 application domains (detailed in Appendix B). Vision and video processing constitutes the largest category (90 tasks, 26.8%), reflecting the growing importance of multimodal media pipelines that involve image segmentation, style transfer, video restoration, scene detection, and diffusion-based generation. Document and web parsing follows with 61 tasks (18.2%), encompassing OCR engines, PDF table extraction, and structured document processing — tasks that demand correct handling of diverse file formats and external parsing dependencies. Web and platform scraping (40 tasks, 11.9%) and development security (40 tasks, 11.9%) each contribute equally, the former testing platform protocol interaction and anti-crawling resilience, the latter exercising static analysis, secret detection, and vulnerability scanning workflows. Speech and audio processing accounts for 36 tasks (10.7%), spanning ASR, voice activity detection, and source separation. Chemistry and molecular analysis provides 30 tasks (8.9%) that require domain-specific knowledge such as retrosynthetic planning and stoichiometric computation. The remaining categories — NLP and string processing (20 tasks, 6.0%), financial backtesting (10 tasks, 3.0%), and web backend frameworks (9 tasks, 2.7%) — round out the distribution, ensuring that the benchmark is not dominated by any single application area. Notably, no single domain exceeds 27% of the total, and the top three domains collectively account for only 56.8%, indicating a reasonably balanced allocation across diverse execution scenarios.
The Multi-Repo split includes 186 tasks, the majority of which require composition across 2-3 domains, while still retaining a small set of more challenging 4-domain workflows. This design ensures evaluation of both domain expertise and cross-domain collaborative execution.
Execution Tasks Complexity.
Figure 4 summarizes the distribution of task difficulty under two complementary notions of complexity.
To objectively evaluate the complexity of single-agent tasks, we have designed a multi-dimensional indicator system. This framework assesses tasks based on environment setup, output predictability, processing patterns, and domain specificity. We define four binary indicators to capture different facets of task difficulty:
•
D1D1 (Constrained Environment): Evaluates whether the environment setup requires system-level dependencies, pre-trained models (>100>100MB), or external network access beyond standard package managers.
•
D2D2 (Uncertain Output): Determines if the task output is non-deterministic due to ML inference variances, external API volatility, or runtime state dependencies.
•
D3D3 (Non-standard Processing): Identifies tasks that deviate from the standard "Input File →\rightarrow Process →\rightarrow Output File" transformation pipeline.
•
D4D4 (Domain Expertise): Measures whether completing the task requires specialized knowledge (e.g., chemistry, finance) beyond general programming and ML engineering.
Tasks are categorized into three tiers: Easy (0-1 indicator satisfied), Medium (2 indicators satisfied), and Hard (3+ indicators satisfied).
For Multi-Repo Tasks, we define Orchestration Complexity to reflect the depth of inter-repository coordination required to complete a workflow. We operationalize this using the collaboration chain length specified during data construction, measured by the number of distinct repositories that must be invoked sequentially, with each agent’s output serving as the input to the next. To isolate interoperability and cross-domain data handoff accuracy from higher-order planning complexity, we restrict workflows to linear dependency chains. Tasks are categorized into three tiers: Easy (2–3 repositories), Medium (4–5 repositories), and Hard (6+ repositories).
4.3 Evaluation Pipeline and Metrics
To evaluate a specific Agentization Method, we perform a comprehensive three-stage assessment covering both the process of agent creation and the quality of the resulting agents.
Stage 1: Agentization Process Assessment.
We first measure the success rate and cost of transforming raw repositories into A2A agents.
•
Agentization Success (Pass@k): We evaluate success based on the deployment verification. An attempt is considered successful if and only if the deployed agent’s AgentCard is retrievable via the A2A endpoint and passes strict schema validation (i.e., contains valid, non-empty tools definitions).
•
Agentization Cost: We record the resource overhead of the agentization lifecycle, specifically reporting Token Consumption per repository.
Stage 2: Capability Inheritance Assessment (Single-Agent).
This stage validates whether the functional value of the repository is effectively activated and execution-ready.
We assess this through one metric:
•
Execution Success Rate (SR): We deploy the Subject Agent into a sandbox to solve Single-Repo Tasks, which require invoking specific tools defined in the AgentCard. We report the Execution Success Rate (SR), verified by an LLM-Judge comparing the agent’s interaction trajectory against the ground truth trajectory.
Stage 3: Collaborative Execution Assessment (Multi-Agent).
This stage evaluates whether an agentization method can produce an agent that can be effectively orchestrated under a user-chosen orchestration mechanism in the Agentic Web: specifically, whether the resulting AgentCard makes the agent’s unique, task-critical capabilities discoverable so that the mechanism can reliably route the right sub-tasks to it (especially when those sub-tasks can only be solved by that agent) during cross-repository collaboration.
The benchmark is designed to be compatible with orchestration mechanisms in any Agentic Web implementation: it provides a pluggable coordination interface, allowing users to configure and plug in their own orchestration strategy (e.g., platform-native orchestrators, planners, or heuristic policies) as long as it can dispatch sub-tasks to A2A agent endpoints and produce execution traces for evaluation.
We report three key metrics:
•
Specification Quality (Orchestrability Proxy): We compare the AgentCard’s Skill Definitions against the annotated Ground Truth Agent Skills and report Skill F1-Score as a proxy for Orchestrability.
•
Orchestration Success Rate (Orch. SR): The percentage of Multi-Repo tasks where all required sub-tasks are correctly dispatched to the appropriate A2A agent endpoints (all-or-nothing, task-level).
•
Multi-Repo Execution Performance (Exec. SR): The percentage of Multi-Repo tasks completed end-to-end, reported conditioned on correct orchestration (i.e., among tasks successful under Orch. SR).
Metric Implementation.
All success determinations leverage a standardized LLM-as-a-Judge framework. The judge compares the agent’s execution results (including terminal outputs and generated artifacts) against the verified ground truth to determine task success.
5 Experiments
In this section, we evaluate our proposed method by instantiating the Agentization Agent on four representative coding-agent frameworks. These frameworks are selected to reflect state-of-the-art capabilities across distinct dimensions of autonomous software engineering.
5.1 Experiment Setup
We evaluate the following four frameworks, representing the state-of-the-art in autonomous software engineering (see Appendix C.1 for the specific driver prompts used to instantiate these agents):
•
Claude Code: An agentic coding tool, instantiated with the Claude-Sonnet-4-5-20250929 model [anthropic2025sonnet45systemcard] in our experiments.
•
Codex CLI: An open source coding agent, driven by the GPT-5.2-Codex [openai2025gpt52codex] backbone.
•
OpenHands [wang2024openhands]: A platform for the development of AI agents, configured with Claude-Sonnet-4-5-20250929 as the backbone.
•
EnvX [chen2025envx]: A coding agent framework specialized in autonomous environment configuration and dependency management, utilizing the Claude-Sonnet-4-5-20250929 model.
Architecture Configuration.
To rigorously assess different agentization methods under a controlled setting, we standardize the agent stack and instantiate a concrete orchestration mechanism (Figure 5) while keeping the benchmark itself orchestration-agnostic.
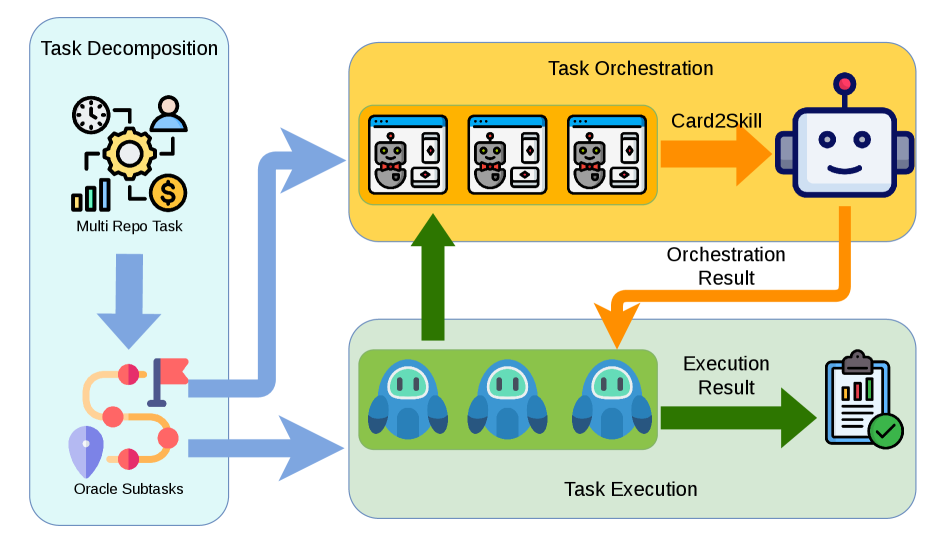
Figure 5: The orchestration mechanism instantiated in our experiments for A2A-Agentization Bench Stage 3. Multi-repo tasks are provided together with their oracle subtask decompositions obtained during benchmark construction, which serve as the input of orchestration process. In parallel, agent cards produced by agentization agent are converted into agent skills. The coordinator relies solely on these skills to select and bind appropriate A2A agents for each subtask, orchestrates their execution and obtains the result.
•
Inner Agent Instantiation: Following the definition in Section 3, we select Claude Code as the reasoning backbone for the Inner Agent (𝒜in\mathcal{A}_{in}). This choice leverages its state-of-the-art tool-use capabilities to effectively drive the extracted repository skills.
•
Orchestration Instantiation (Claude Code + Oracle Decomposition). For the Multi-Agent evaluation, we instantiate a centralized orchestration setup driven by Claude Code (Figure 5). We initialize each Multi-Repo task with its ground-truth decomposition from the data construction, and convert the generated AgentCards of the 35 A2A agents into executable Claude Agent Skills [anthropic_agent_skills_overview]. Claude Code then relies solely on these AgentCard-derived skill specifications to retrieve/bind agents and dispatch all sub-tasks via the A2A protocol.
5.2 Main Results
We present our experimental findings following the three-stage evaluation pipeline defined in Section 4.3.
Stage 1: Agentization Process Assessment.
Table 1 reports the success rate and cost of the agent creation process. Both Claude Code and EnvX achieve a perfect 100% Agentization Success (Pass@1), demonstrating the robust reasoning capabilities of the underlying model in following the schema retrieval instructions. EnvX consumes slightly more tokens (4.2M vs 3.3M) due to its additional autonomous verification and environment configuration steps. In contrast, other baselines exhibit lower reliability, even requiring up to three attempts to successfully configure certain repositories.
Table 1: Stage 1 Results: Agentization Process Assessment. We report Pass@1 and Pass@3 in percentage (%).
Framework
Pass@1 ↑\uparrow
Pass@3 ↑\uparrow
Tries ↓\downarrow
Tokens ↓\downarrow
Claude Code
100.00
100.00
1.000
3374449
Codex
94.28
100.00
1.086
2321397
OpenHands
94.28
100.00
1.057
3254978
EnvX
100.00
100.00
1.000
4215051
Stage 2: Capability Inheritance Assessment.
This stage validates the functional fidelity of the agentized repositories through Single-Repo task execution. Table 2 shows that Claude Code achieves the highest Overall Success Rate of 36.9%. EnvX follows closely with a 35.1% success rate, while demonstrating superior efficiency in token consumption. This efficiency stems from the solid environment configuration established during the Agentization stage; unlike other methods that often require runtime environment troubleshooting, EnvX operates within a pre-verified environment, minimizing the need for corrective steps during execution. Finally, Codex (34.5%) outperforms OpenHands (33.9%), though both lag behind the top performers.
We employ an LLM-as-a-Judge mechanism to evaluate the skill coverage, using the prompt detailed in Appendix C.2.
Table 2: Stage 2 Results: Capability Inheritance. We report Execution Success Rate (SR, %) for task execution.
Framework
Execution SR (%) ↑\uparrow
Easy
Medium
Hard
Overall
Claude Code
57.9
38.5
10.4
36.9
Codex
45.2
42.3
14.2
34.5
OpenHands
54.8
32.7
10.4
33.9
EnvX
53.2
38.5
10.4
35.1
Stage 3: Collaborative Execution Assessment.
Finally, we evaluate the agents’ Orchestrability in a multi-agent environment where the central Orchestrator is kept fixed. We first measure Skill F1 as a metric of Specification Quality, evaluating how effectively the Agentization method constructs an Agent Card to present its functionalities. This metric is calculated by comparing the generated skill descriptions against the Ground Truth agent capabilities. As shown in Table 3, both EnvX (66.2%) and Claude Code (63.0%) achieve high Skill F1 scores, suggesting superior self-description capabilities.
This high specification quality correlates positively with Orchestration Success Rate (Orch. SR). Notably, in Hard scenarios requiring long-chain reasoning, agents with higher Skill F1 scores (EnvX and Claude Code) maintain significantly higher robustness (44.4%) compared to others (≈\approx25-30%). However, regarding final Execution Success Rate (Exec. SR), OpenHands achieves the highest Overall Execution SR (46.2%) despite having the lowest Orchestration SR (65.1%). This result reinforces the findings from the Capability Inheritance Assessment (Stage 2), highlighting the exceptional robustness of the OpenHands execution engine, which remains highly effective even in complex collaborative settings.
Table 3: Skill Specification Quality: Precision, Recall, and F1 (in %).
Framework
Precision ↑\uparrow
Recall ↑\uparrow
F1 ↑\uparrow
Claude Code
70.4
70.4
63.0
Codex
50.0
47.8
42.1
OpenHands
65.2
69.7
59.9
EnvX
69.8
74.0
66.2
Table 4: Stage 3 Results: Collaborative Execution. We report Orchestration SR (Orch., %) and Execution SR (Exec., %). Collaboration Chain Length: Easy=2–3, Med=4–5, Hard=6+.
Easy
Medium
Hard
Overall
Framework
Or.SR ↑\uparrow
Ex.SR ↑\uparrow
Or.SR ↑\uparrow
Ex.SR ↑\uparrow
Or.SR ↑\uparrow
Ex.SR ↑\uparrow
Or.SR ↑\uparrow
Ex.SR ↑\uparrow
Claude Code
81.6
48.0
67.2
39.3
44.4
7.4
71.5
39.2
Codex
83.7
54.1
59.0
32.8
25.9
7.4
67.2
40.3
OpenHands
81.6
63.3
54.1
34.4
29.6
11.1
65.1
46.2
EnvX
83.7
61.2
57.4
23.0
44.4
11.1
69.4
41.4
5.3 Analysis
Based on the experimental results, we further analyze the failure patterns across the agent’s lifespan. Our comparative analysis identifies three critical optimization directions for Agentization, aiming to resolve bottlenecks spanning from environment configuration and skill construction to autonomous self-description.
Challenge 1: Environment Pre-configuration.
Failures in environment pre-configuration stem from the inability to resolve system dependencies, manifesting as Startup Failures, A2A Schema Non-compliance, or most frequently, Unusable Skills. These failures force agents into costly runtime troubleshooting or raw terminal usage (hand-crafting), which significantly inflates token consumption.
This operational overhead is starkly illustrated by the aizynthfinder trajectory, wherein an unconfigured environment forced the agent to expend 6.5 minutes executing 22 distinct package management operations (see Appendix A.1). Such toolchain misalignments ultimately necessitated a disproportionate synchronization of over 150 packages merely to resolve a single dependency, underscoring the severity of the debugging loop.
Challenge 2: Skill Construction.
Failures in skill construction arise from unverified alignment between generated code and repository implementation, typically appearing as Hallucinated APIs (non-existent functions) or Incorrect Signatures. The segment-anything trajectory exemplifies this fragility: the segment_with_points tool repeatedly rejected valid semantic inputs due to a type signature mismatch (expecting objects but receiving strings) (see Appendix A.2). Unable to resolve this misalignment, agents are forced to abandon encapsulated skills in favor of unstable raw code generation. This failure mode proves systemic, with analysis revealing that 100% of segmentation tool calls failed due to similar implementation defects, driving the bypass of efficiency-enhancing abstractions.
Challenge 3: Capability Specification.
This challenge concerns the construction of the Agent Card, which serves as the agent’s functional profile and advertisement on the Agentic Web. Failures in self-description bottleneck collaboration by blurring tool implementation with functional advertisement. Generic descriptions prevent the Orchestrator from distinguishing specific agent roles. This is prominently evident in OpenHands (Table 4), where dispatch failures stem from two distinct mechanisms. First, semantic blurring caused the incorrect deployment of the speechbrain_agent due to broad advertisements that overshadowed the specialized spleeter_agent (see Appendix A.3). Second, structural indistinguishability occurred where chemlib and chemformula shared identical "Generic repository agent" profiles. These ambiguities force the orchestrator to abandon deterministic role matching in favor of error-prone heuristic guessing.
6 Conclusion
In this paper, we study the supply-side challenge of the Agentic Web and conceptualize agentization as the process of transforming digital assets, such as passive software repositories, into interoperable agents. We outline a basic agentization workflow and use it to systematically examine the difficulties encountered when activating real-world code repos. Our extensive experiments reveal that successful agentization hinges on three critical pillars: robust Environment pre-configuration, reliable Skill Construction, and clear self-description to enable effective multi-agent collaboration. By identifying these core challenges, we provide a roadmap for future research to bridge the gap between isolated software tools and a fully interconnected Agentic Web.
References
Appendix A Case Study
In this section, we present a collection of representative execution trajectories and examples that illustrate the diverse failure modes and decision-making challenges analyzed in the case studies.
A.1 Case 1: Environment Pre-configuration
Listing 1: Aizynthfinder Agent Environment Configuration Trajectory (Simplified)
[VENV_PATH]/bin/pip install python-docx
.venv/bin/pip install python-docx
.venv/bin/python3 -m pip install python-docx
which uv
uv pip install python-docx
python3 run_retroplanning.py
sed -i ’17,19d’ run_retroplanning.py
source .venv/bin/activate && uv pip install -e .
uv sync
source .venv/bin/activate && uv pip install rdchiral rdkit aizynthfinder
uv pip install python-docx --python .venv/bin/python3
A.2 Case 2: Skill Construction
Listing 2: The provided trajectory exemplifies the fragility of skill construction.
{
"index": 1,
"timestamp": "2026-01-07T15:06:00.574575",
"type": "AssistantMessage",
"data": {
"content": [
{
"text": "I’ll segment the dog from the background using the Segment Anything Model with the point prompt you provided."
}
],
"model": "claude-sonnet-4-5-20250929",
"parent_tool_use_id": null,
"error": null
}
},
{
"index": 2,
"timestamp": "2026-01-07T15:06:01.596017",
"type": "AssistantMessage",
"data": {
"content": [
{
"id": "toolu_011zcKdQ6vnc2gRjJhREtDpi",
"name": "mcp__repo__segment_with_points",
"input": {
"image_path": "/tmp/a2a_agent_05gvew92/dog.jpg",
"point_coords": "500, 400",
"point_labels": "[1]",
"model_type": "vit_h"
}
}
],
"model": "claude-sonnet-4-5-20250929",
"parent_tool_use_id": null,
"error": null
}
}
A.3 Case 3: Capability Specification
Listing 3: Spleeter Agent Agentcard configured by OpenHands
{
"capabilities": {
"streaming": false
},
"defaultInputModes": [
"text/plain",
"audio/mpeg",
"audio/wav"
],
"description": "AI-powered audio source separation agent using Spleeter.",
"name": "spleeter_audio_separation_agent",
"version": "1.0.0"
}
Appendix B Repositories Used to Build the A2A-Agentization Benchmark
The repositories are organized by domain, as described below.
1) Document and Web Parsing with OCR
•
Tesseract: A classic open-source OCR engine primarily written in C++, featuring multilingual support and a large ecosystem.
GitHub: https://github.com/tesseract-ocr/tesseract•
EasyOCR: An out-of-the-box OCR solution based on PyTorch, supporting more than 80 languages and suitable for rapid integration.
GitHub: https://github.com/JaidedAI/EasyOCR•
textract: A unified interface for extracting plain text from almost any document format (e.g., Word, PDF), often relying on external engines.
GitHub: https://github.com/deanmalmgren/textract•
•
•
•
2) Web and Platform Scraping for Text Acquisition
•
trafilatura: A tool for extracting main content and metadata from web pages, supporting command-line and batch processing.
GitHub: https://github.com/adbar/trafilatura•
•
•
MediaCrawler: A crawler framework for collecting content and comments from platforms such as Xiaohongshu, Douyin, Kuaishou, Bilibili, Weibo, Tieba, and Zhihu.
GitHub: https://github.com/NanmiCoder/MediaCrawler
3) Speech and Audio Processing (ASR, VAD, Separation, End-to-End Systems)
•
•
ESPnet: An end-to-end speech processing toolkit covering ASR, TTS, and speech translation.
GitHub: https://github.com/espnet/espnet•
•
spleeter: A music source separation tool for isolating vocals and accompaniment using pretrained models.
GitHub: https://github.com/deezer/spleeter
4) Vision and Video Processing and Generation
•
•
Ultralytics: Official implementations and toolchains for the YOLO family, including object detection, segmentation, and pose estimation.
GitHub: https://github.com/ultralytics/ultralytics•
•
•
•
•
moviepy: A Python-based video editing framework supporting clipping, concatenation, effects, and text overlays.
GitHub: https://github.com/Zulko/moviepy•
•
5) Development Security and Vulnerability Detection
•
Bandit (PyCQA): A static analysis tool for identifying common security issues in Python codebases.
GitHub: https://github.com/PyCQA/bandit•
•
•
Bolt (s0md3v): A scanner designed to detect Cross-Site Request Forgery (CSRF) vulnerabilities.
GitHub: https://github.com/s0md3v/Bolt
6) NLP, String Processing, and Prompt Engineering
- •
- •
7) Chemistry, Molecular Analysis, and Synthesis Planning
•
•
•
chemlib: A general-purpose Python library for chemical calculations, periodic table access, and stoichiometry.
GitHub: https://github.com/harirakul/chemlib
8) Web, Backend, and General Frameworks
•
bottle: A lightweight Python web microframework that can be deployed as a single-file application.
GitHub: https://github.com/bottlepy/bottle
9) Financial Backtesting
•
backtrader: A quantitative trading strategy backtesting framework supporting multiple data feeds, commissions, visualization, and optimization.
GitHub: https://github.com/mementum/backtrader
Appendix C Prompts
C.1 Agentization Prompt
This section presents the prompts used to invoke four distinct frameworks for the agentization process.
Claude Code ``` Codex `` Openhands `EnvX` `` ```
``````````` `````````` ### C.2 Agent skill Judge Prompt #### Prompt: Skill Coverage Judgement. This prompt judges whether a test skill is covered by a target skill set, based on actual capability. `Prompt: Skill Coverage Judgement` ````````` ### C.3 Single-Repo Data Generation Prompts #### Prompt 1: Repository Capability Analysis and Task Ideation. This prompt requests a structured capability summary of the repository and a set of lightweight, file-producing evaluation tasks. `Prompt 1: Repository Capability Analysis and Task Ideation` ```````` #### Prompt 2: Task Specification and Feasibility Validation. This prompt converts the proposed tasks into reproducible task files and validates feasibility by executing each task once. `Prompt 2: Task Specification and Feasibility Validation` ``````` #### Prompt 3: Judge Standard Extraction from Verified Runs. This prompt extracts concrete evaluation steps and a standardized expected response from verified execution logs. `Prompt 3: Judge Standard Extraction` `````` #### Prompt 4: Consolidation into a Single JSON Dataset. This prompt consolidates all validated tasks into a single structured JSON file suitable for downstream benchmark ingestion. `Prompt 4: JSON Consolidation` ````` ### C.4 Multi-Repo Data Generation Prompts `` Multi-Repo Task Generation Search Agent Prompt `Multi-Repo Task Generation Code Agent Prompt` `` ```` ``` ## Appendix D Human Check Criteria on Tasks This section presents the human check criteria on single-repo tasks and multi-repo tasks. ### D.1 Single-Repo Tasks Human Check Criteria `Single-Repo Tasks Human Check Criteria` `` ### D.2 Multi-Repo Tasks Human Check Criteria `Multi-Repo Tasks Human Check Criteria` `` ``` ```` ````` `````` ``````` ```````` ````````` `````````` ```````````